บันทึกการแก้ไข kohya-ss sd-scripts เพื่อให้ได้ตามความต้องการ
sd-scripts คืออะไร?
sd-scripts คือ python scripts ที่ใช้สำหรับการ Fine Tuning โมเดล Stable Diffusion (รวมถึง Flux) โดยเป็น command line interface ซึ่งเวลาจะ Fine Tuned ใดๆ คือต้องมีความรู้ เรื่องการใช้งาน command line และรู้จัก parameters ทุกตัวที่ใช้ในการ Fine Tuned Stable Diffusion Model ใดๆ
ใช้งานยังไง?
เรียกไฟล์ python ผ่านโปรแกรม accelerate พร้อมไฟล์ python ที่ต้องการ และต้องใส่ args ลงไปเรื่อยๆ
ตัวอย่างของ Flux LoRA Training (จาก github sd-scripts)
accelerate launch --mixed_precision bf16 --num_cpu_threads_per_process 1 flux_train_network.py
--pretrained_model_name_or_path flux1-dev.safetensors --clip_l sd3/clip_l.safetensors --t5xxl sd3/t5xxl_fp16.safetensors
--ae ae.safetensors --cache_latents_to_disk --save_model_as safetensors --sdpa --persistent_data_loader_workers
--max_data_loader_n_workers 2 --seed 42 --gradient_checkpointing --mixed_precision bf16 --save_precision bf16
--network_module networks.lora_flux --network_dim 4 --network_train_unet_only
--optimizer_type adamw8bit --learning_rate 1e-4
--cache_text_encoder_outputs --cache_text_encoder_outputs_to_disk --fp8_base
--highvram --max_train_epochs 4 --save_every_n_epochs 1 --dataset_config dataset_1024_bs2.toml
--output_dir path/to/output/dir --output_name flux-lora-name
--timestep_sampling shift --discrete_flow_shift 3.1582 --model_prediction_type raw --guidance_scale 1.0
ทำไมถึงต้องแก้ sd-scripts

จาก issue นี้ มี pain point หลักๆ คือ
- SDXL เวลาเทรน LoRA ประกอบไปด้วย Unet คือส่วนที่ทำการเจนภาพ และ Text Encoder 2 (CLIP-L + CLIP-G) ตัว ที่ทำให้เข้าใจ prompt เพื่อส่งต่อไปยัง Unet ซึ่งคนทั่วไปคงไม่ได้คิดอะไรหรอกว่า อ่าว เทรน Text Encoder ด้วยก็ดีหนิ ทำให้รู้จัก Prompt มากขึ้นด้วย แต่การที่มี 2 ตัวแล้วจากที่เทรนจะมีปัญหาหลักๆ คือ
-
CLIP-L ทนทานต่อ overfitting มาก ๆ คือต่อให้เทรน CLIP-L มากแค่ไหนก็ยังไม่เกิดอาการ overfitting ได้ (ทำให้เกิดขึ้นได้แต่ยาก)
-
CLIP-G ตัวนี้คือตัวปัญหาใหญ่ในการเทรนเลยคือ มีการออกอาการ Overfitting ง่ายมาก แล้วอาการนี้ทำให้ LoRA ที่เทรนมาคือเจนออกมาเป็นภาพเดิมๆ, prompt 1 คำออกมาไม่ตรง, ใส่ 1girl แล้วตัวละครออกเลย จะเกิดอาการแบบนี้
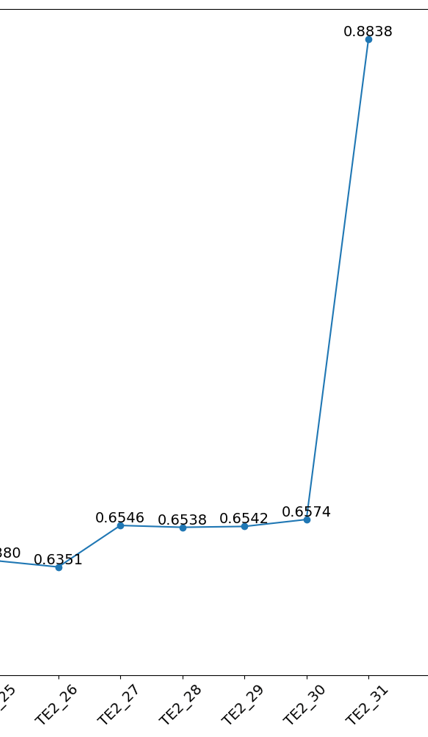
ภาพ CLIP-G (TE2) ไหม้โดยเฉพาะ block ที่ 31
ในปัจจุบัน sd-scripts ในการตั้ง Learning Rate ของ Text Encoder ได้แค่ค่าเดียวคือตั้ง --text-encoder-lr 1e-4 แล้วก็คือไปตั้ง Text Encoder ทั้ง 2 ตัวเลย แต่ที่แปลกคือทำไม Flux ถึงแยกได้คือตั้ง CLIP-L กับ T5XXL ก็เลยมี issue นี้ขึ้นมา
แนวทางการแก้ปัญหาอาการ CLIP-G (TE2) ไหม้
- จับ fork repo https://github.com/kohya-ss/sd-scripts/ นี้ก่อนเลย
- แยก Learning Rate ให้ต่างกันให้ได้
- เวลาเทรน LoRA SDXL ให้เลือกเอาแค่ Unet + CLIP-L (TE1) เท่านั้นได้
เป้าหมาย
-
code เดิมต้องอยู่ และใช้การเติมเอาเพราะว่า อนาคต sd-scripts ของต้นทางอาจจะมีการแก้ไขส่วนอื่นได้
-
สิ่งที่เติมมาต้องไม่กระทบการเทรน LoRA เดิม และไม่ต้องมีการแก้ไข args ใดๆ
-
หากมีการเพิ่ม feature ให้เพิ่ม args แทน
สิ่งที่ต้องหาคือ script sdxl_train_network.py ทำงานยังไง
- เวลาการตั้ง Learning Rate คือมาจากการสร้างไฟล์ network module ขึ้นมาแล้วกำหนด Learning Rate เข้าไป สิ่งที่ค้นหาไปเรื่อยๆ แล้วเจอว่าสร้าง LoRA จากไฟล์นี้ networks/lora.py พอไปดูที่เวลากำหนดรูปแบบของ LoRA ก็เห็นว่าเป็น networks.lora ก็คิดได้แล้วว่าตรงเป๊ะ
ฟังก์ชันที่ใช้กำหนด Learning Rate + Scheduler + Optimizer คือ prepare_optimizer_params แล้วเห็นว่าไม่ได้มีการแยก Learning Rate ของ text encoder เลย
- จะทำยังไงให้แยกได้โดยไม่แก้ code เดิมเลย ก็ใช้วิธีการไป copy code ของ lora_sd3.py ฟังก์ชันที่มีชื่อว่า
prepare_optimizer_params_with_multiple_te_lrs
แล้วเอามาให้หมดมาแปะที่ lora.py
ทำไมถึงต้องเป็น function นี้
เพราะว่าเวลาที่ใช้ในการเทรนตามแนวคิดของ OOP คือ sdxl_train_network.py เป็น class ที่สืบทอดมาจาก train_network.py อีกทีหนึ่ง (แนวคิดของ OOP ขอไม่เจาะลึก) แล้วไปเจอมาว่ามีการเรียก function นี้
support_multiple_lrs = hasattr(network, "prepare_optimizer_params_with_multiple_te_lrs")
เป็นการตรวจสอบว่า network ที่เรียกใช้ในการเทรน (ประเภทของ LoRA ที่จะสร้าง) มี่ attribute นี้หรือไม่ เลยเลือกใช้
prepare_optimizer_params_with_multiple_te_lrs
ในการเติมลงไปใน lora.py เข้าไป
copy แล้วไม่เท่ากับว่า ใช้ได้เลย
-
บางคนอาจจะคิดว่าเอ๊ะถาม LLM ก็ได้หนิว่าแก้ code ของ SD3 ที่มี Text Encoder 3 ตัวเลย ให้เหลือ 2 ตัวได้มั้ย จริงๆ อาจได้ แต่ว่าการแก้เองเวลาเจอปัญหาจะรู้จุดที่ต้องแก้ได้ง่ายกว่าด้วย
-
ที่ไม่ copy ของ Flux เพราะว่า SD3 มีความใกล้เคียงมากกว่า Flux
# for sdxl have only two LR
if text_encoder_lr is None or (
isinstance(text_encoder_lr, list) and len(text_encoder_lr) == 0
):
text_encoder_lr = [default_lr, default_lr]
elif isinstance(text_encoder_lr, float) or isinstance(text_encoder_lr, int):
text_encoder_lr = [float(text_encoder_lr), float(text_encoder_lr)]
elif len(text_encoder_lr) == 1:
text_encoder_lr = [text_encoder_lr[0], text_encoder_lr[0]]
elif len(text_encoder_lr) == 2:
text_encoder_lr = [text_encoder_lr[0], text_encoder_lr[1]]
...
# TE1 (CLIP-L)
logger.info(
f"Text Encoder 1 (CLIP-L): {len(te1_loras)} modules, LR {text_encoder_lr[0]}"
)
params, descriptions = assemble_params(
te1_loras, text_encoder_lr[0], loraplus_lr_ratio
)
# TE2 (CLIP-G)
logger.info(
f"Text Encoder 2 (CLIP-G): {len(te2_loras)} modules, LR {text_encoder_lr[1]}"
)
params, descriptions = assemble_params(
te2_loras, text_encoder_lr[1], loraplus_lr_ratio
)
สิ่งที่แก้ไปคือ ตัด text_encoder_lr ให้เหลือแค่ 2 ตัวก่อน และให้เวลาตั้ง Learning Rate ให้แยกกันได้
code บางส่วนที่เห็นคือก็สามารถแยกออกจากกันได้แล้ว
ตรวจสอบว่าแยก Learning Rate CLIP-L กับ CLIP-G ได้แล้วยังไง
- ตั้ง parameters ที่ให้เทรน LoRA แบบไม่ต้อง warmup
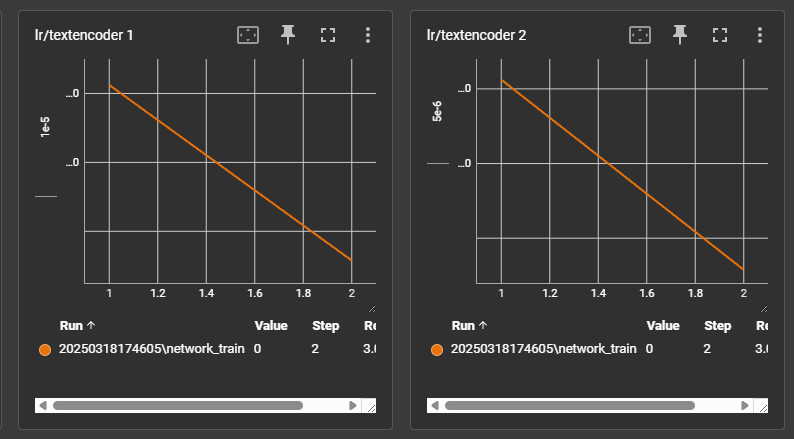
พบว่าแยก Learning Rate ออกจากกันได้แล้ว
การที่จะเอา CLIP-G ออก
- ไอเดียของผมคือ แก้ให้น้อยที่สุดก็คือเติม network args ลงไปเพิ่ม
สิ่งที่เพิ่มเข้าไปคือ clip_l_only หมายถึงเวลาเทรน LoRA SDXL ให้มีแค่เฉพาะ CLIP-L เป็น text encoder ที่ถูกเทรนเข้าไปด้วย เวลาใช้งานคือ
--network_args clip_l_only=true แบบนี้เป็นต้น
args นี้คือเป็นการดักจุดในการสร้าง module ง่ายๆ เลยคือเวลาสร้าง text encoder module ให้ break ออกไปเลยและเติม log ให้ดูออกว่า skip แล้วนะ (อาจจะไม่ใช่วิธีที่ดีที่สุด)
if i == 1 and train_clip_l_only:
logger.info(f"skip CLIP-G training")
break
ทดสอบว่า CLIP-G หายไปแล้ว
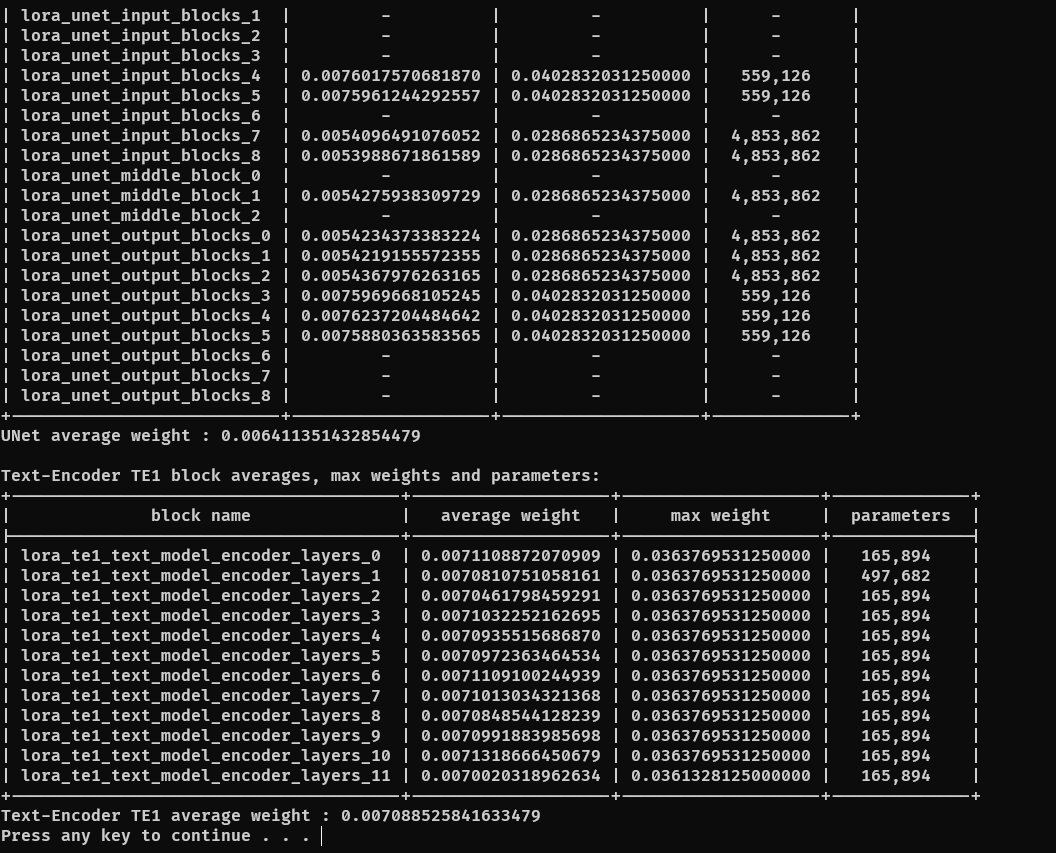
- ใช้โปรแกรมเช็ค LoRA ว่าประกอบด้วยอะไรบ้างในการตรวจสอบซึ่งพบว่าหายไปจริง
ปัญหาที่เจอหลังใช้งานไปได้สักพัก
- block weight ไม่ทำงาน -> แก้ด้วยการผสม code ที่เรียก block weight จาก function เก่าคือ
if self.unet_loras:
if self.block_lr:
is_sdxl = False
for lora in self.unet_loras:
if (
"input_blocks" in lora.lora_name
or "output_blocks" in lora.lora_name
):
is_sdxl = True
break
# 学習率のグラフをblockごとにしたいので、blockごとにloraを分類
block_idx_to_lora = {}
for lora in self.unet_loras:
idx = get_block_index(lora.lora_name, is_sdxl)
if idx not in block_idx_to_lora:
block_idx_to_lora[idx] = []
block_idx_to_lora[idx].append(lora)
# blockごとにパラメータを設定する
for idx, block_loras in block_idx_to_lora.items():
params, descriptions = assemble_params(
block_loras,
(unet_lr if unet_lr is not None else default_lr)
* self.get_lr_weight(idx),
self.loraplus_unet_lr_ratio or self.loraplus_lr_ratio,
)
all_params.extend(params)
lr_descriptions.extend(
[
f"unet_block{idx}" + (" " + d if d else "")
for d in descriptions
]
)
else:
params, descriptions = assemble_params(
self.unet_loras,
unet_lr if unet_lr is not None else default_lr,
self.loraplus_unet_lr_ratio or self.loraplus_lr_ratio,
)
all_params.extend(params)
lr_descriptions.extend(
["unet" + (" " + d if d else "") for d in descriptions]
)
เอามาแปะแทนของใหม่ ก็สามารถทำให้ Train LoRA แบบ block weight ได้แล้ว
logs ที่ใช้ในการตรวจสอบ พบว่าแบ่งออกเป็นกลุ่มๆ แล้ว แสดงว่า block weight ได้สำเร็จ
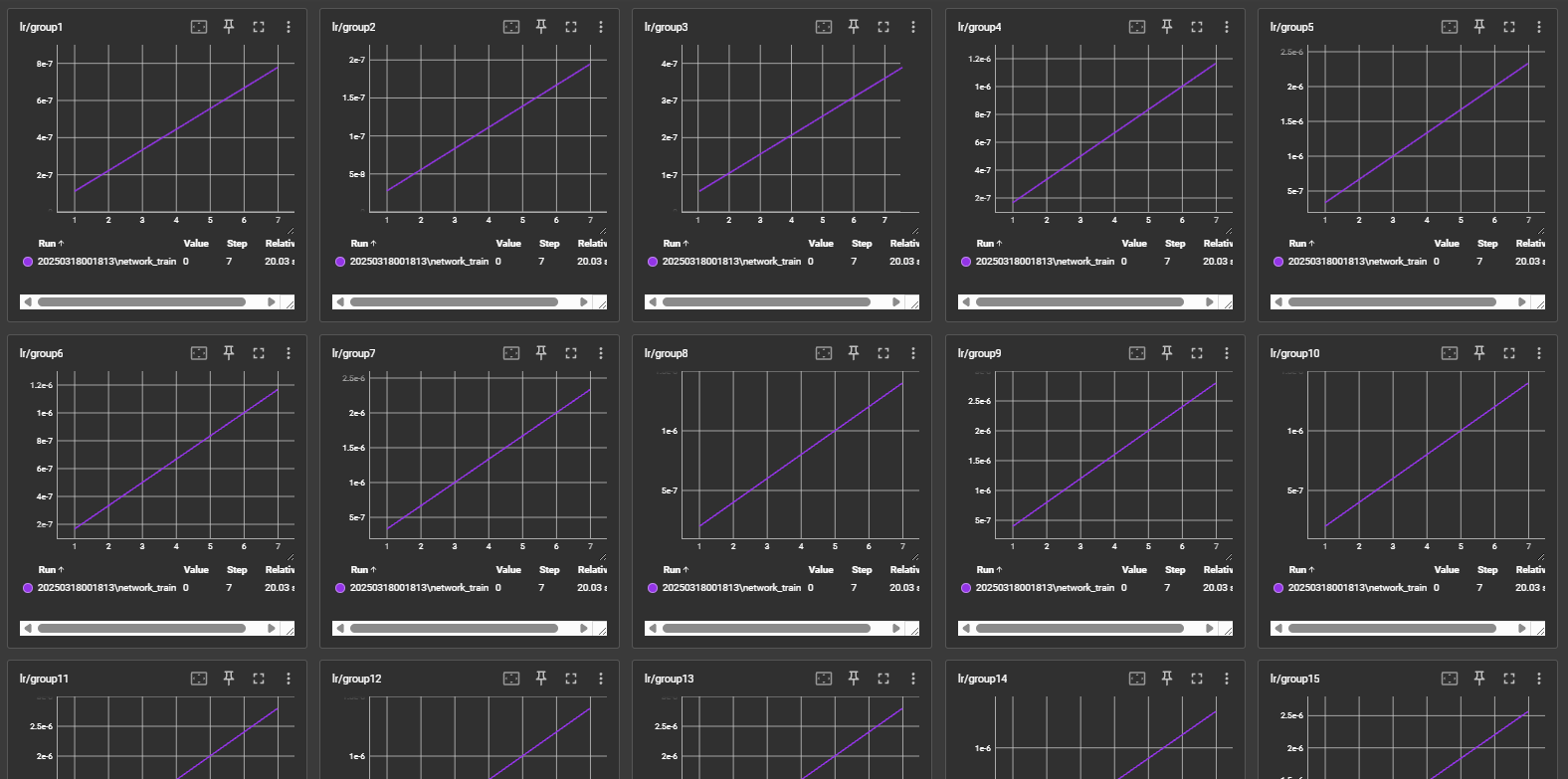
การ Update kohya-ss GUI

- ในส่วนของ GUI จะมีการเติมช่อง CLIP-G learning rate เข้าไป
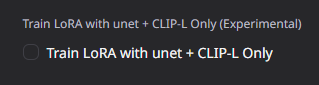
- มีการเพิ่มช่องติ๊กถูกในการเทรน LoRA SDXL แบบ Unet + CLIP-L
- ปรับ theme ให้ตรงตามความต้องการ (เพื่อความสวยงาม)
- เปลี่ยนเลข version เป็น v24.4.1
สิ่งที่ได้จากการแก้ไข script นี้
- กระบวนการเทรน LoRA โดยการอ่าน code ทีละส่วน และ การแก้ปัญหาที่ให้ได้ตามความต้องการโดยไม่ต้องรอเจ้าของแก้ให้เนื่องจากเป็น open source program เลยสามารถทำได้
- เทรน LoRA SDXL ได้ง่ายขึ้น (มั้งนะ)
- ปล่อย LoRA ตัวใหม่ๆ มา ช่วยแก้ปัญหาหลายๆ เรื่องไปได้
Link Repo ที่มีกล่าวถึง
- kohya-ss GUI https://github.com/bmaltais/kohya_ss
- sd-scripts https://github.com/kohya-ss/sd-scripts/tree/sd3
