มาลอง Quantization Flux Model ใดๆด้วยวิธี GGUF กันเถอะ

UPDATE
- มีการเพิ่มวิธีใหม่เข้าไปทำได้ง่ายกว่าเดิม อ่านได้ที่ วิธีใหม่ (ง่ายมาก)
บทความนี้เป็นการแปลงโมเดลโดยเป็นการย่อขนาดโมเดล FP16 ให้เหลือขนาด GGUF ที่ต้องการ ซึ่งอาจจะมีความซับซ้อนในการทำในแต่ละขั้นตอน
วิธีใหม่ (ง่ายมาก)
สเปคที่ต้องการ
- RAM 32 GB ขึ้นไป
- พื้นที่ 35 GB ขึ้นไป (Flux FP16 23 GB + Flux GGUF Q ต่างๆ 3-11 GB)
โปรแกรมที่ต้องการ
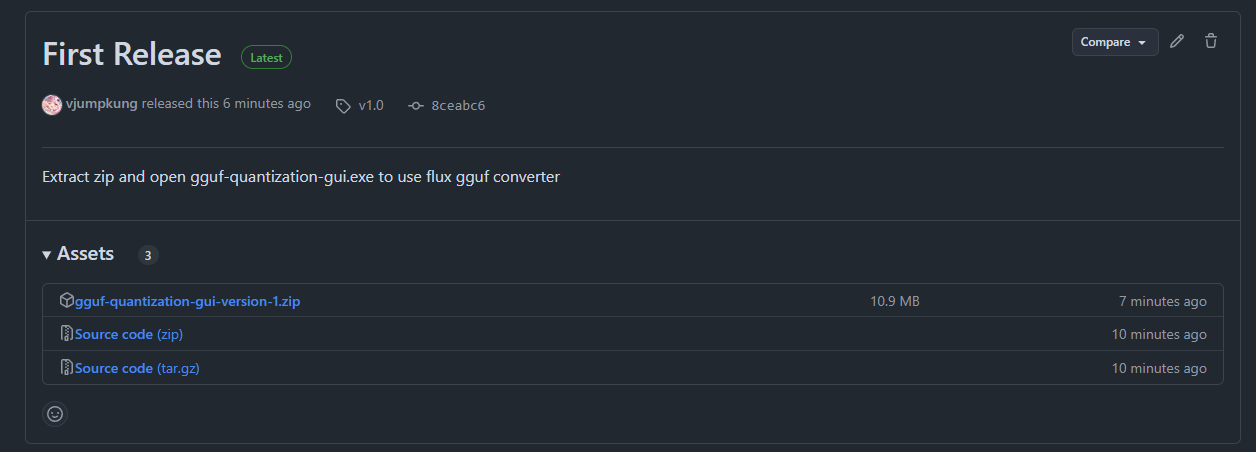
- .exe version Downlaod ได้จาก Link นี้
- python version (windows กด setup.bat แล้ว run-gui.bat หากไม่สามารถ download .exe ได้) Link นี้
- source code (หากต้องการดู) https://github.com/vjumpkung/flux_gguf_converter_gui
ขั้นตอนการใช้งาน
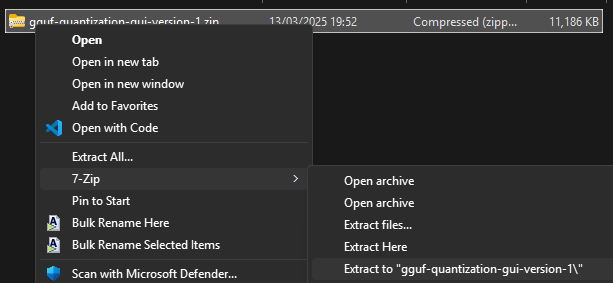
- แตกไฟล์
gguf-quantization-gui-version-1.zip
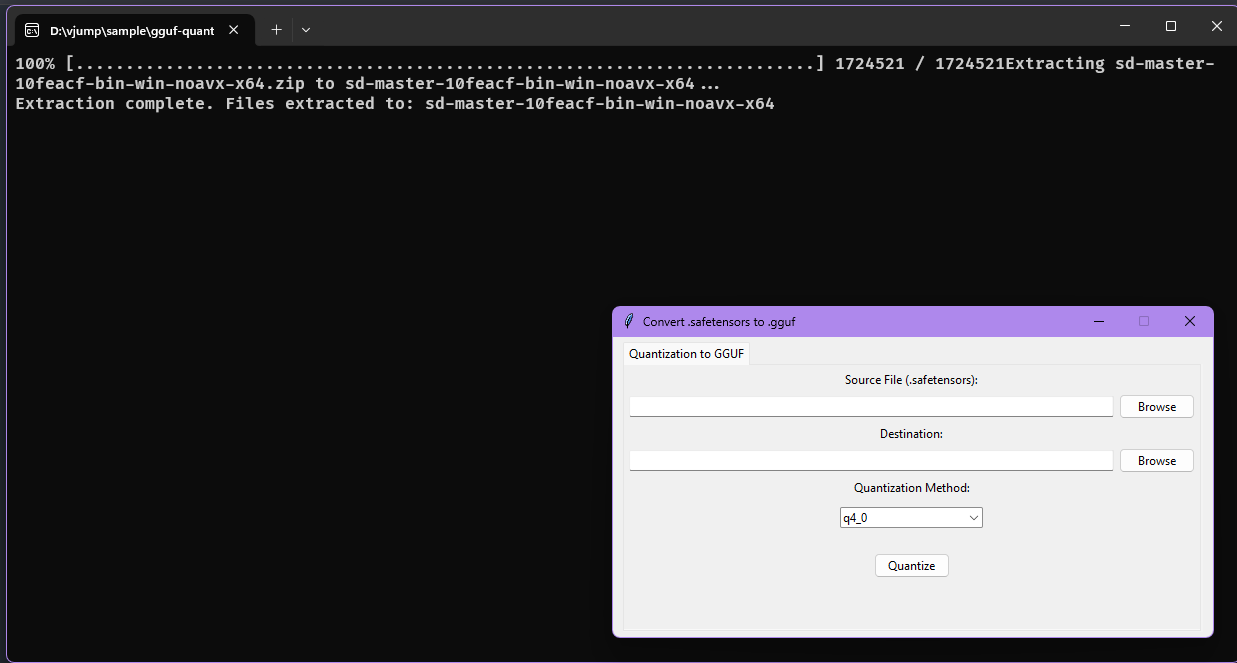
-
เปิดโปรแกรม
gguf-quantization-gui.exe(หากติด smartscreen ให้ run-anyway) -
เลือกไฟล์ Flux UNet .safetensors โดยเป็นขนาด fp16 (fp8 ทำได้เช่นกัน)
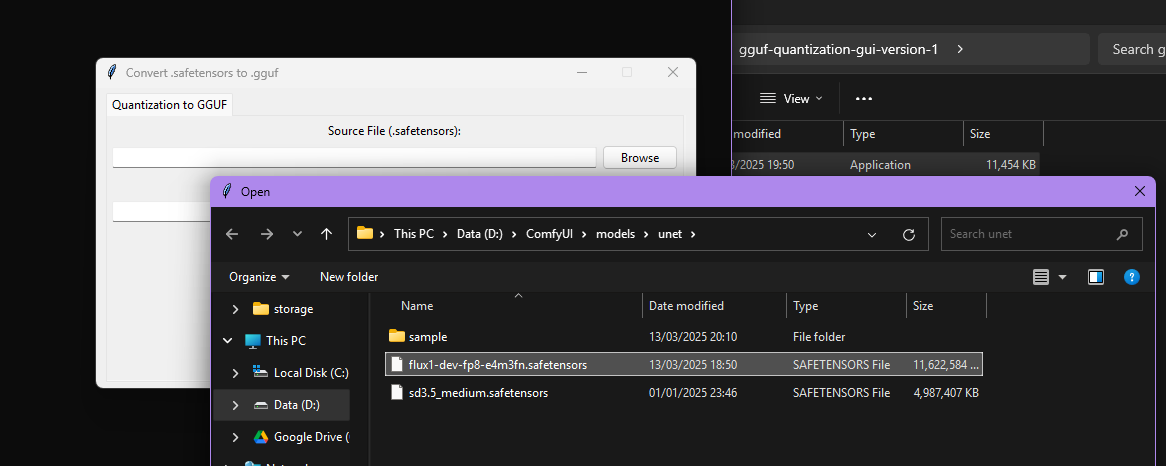
- เลือกตำแหน่งที่จะ save file GGUF ออกมา
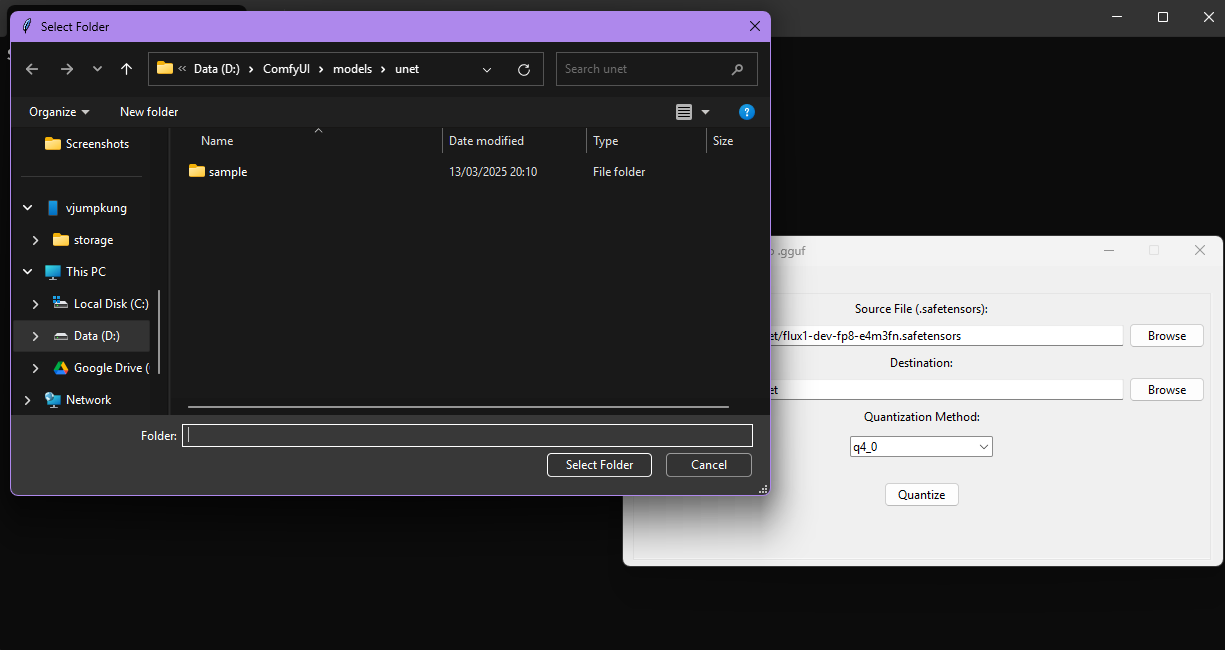
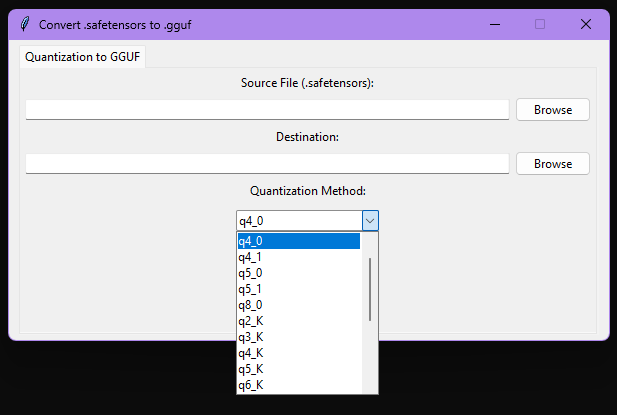
- กดเลือก Quantization Method โดยมีขนาดดังนี้
- VRAM 6 GB ใช้ q2_K
- VRAM 8 GB ใช้ q3_K
- VRAM 12 GB ใช้ q4_K อาจได้ถึง q5
- VRAM 16 GB (แนะนำให้ใช้ตัว fp8 ไปเลย)
- VRAM 24 GB (แนะนำให้ใช้ตัว fp8 ไปเลย)
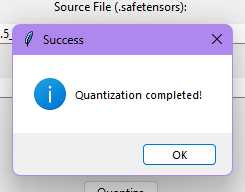
- กดปุ่ม Quantize และรอสักพัก เมื่อ Quantization สำเร็จแล้วจะมีไฟล์นี้ปรากฏขึ้นมา และหน้าต่างแจ้งการแปลงสำเร็จ

- นำ model gguf ไปใช้
- ComfyUI ใส่ไปที่ folder models/unet
- WebUI Forge ใส่ไปที่ models/stable-diffusion/
สรุปข้อดีของ Flux GGUF
- ขนาดไฟล์เล็กลงทำให้ใช้ในการ์ดจอที่ vram ต่ำได้
- ใช้งาน LoRA ได้เหมือน Flux ปกติ
ข้อเสีย
- ความเร็วในการประมวลผลช้าลงเมื่อเทียบกับการ์ดจอที่ vram สูง
วิธีแบบดั้งเดิม
สเปคที่ต้องการ
- RAM 32 GB ขึ้นไป
- พื้นที่ 50 GB ขึ้นไป (Flux FP16 23 GB +Flux GGUF F16 23 GB + Flux GGUF Q ต่างๆ 3-11 GB)
โปรแกรมที่ต้องการ
- CMake
- Visual Studio 2019 ขึ้นไป (น่าจะใช่) (ผู้เขียนใช้ Visual Studio 2022)
- python 3.10 ถึง 3.12 ที่ลง torch, gguf, safetensors, tqdm หากยังไม่ได้ติดตั้งให้ทำการ pip install… ก่อน
โมเดลที่ต้องการ
- Flux FP16 หรือ FP8 เป็นในส่วนของ unet เท่านั้น โดยสามารถเลือกได้ในตาม CivitAI หรือ Huggingface
pip install torch gguf safetensors tqdm
Guide นี้จะเป็นการแปลจาก https://github.com/city96/ComfyUI-GGUF/tree/main/tools เป็นหลัก
ขั้นตอนที่ 1 Compile โปรแกรมให้เรียบร้อยก่อน
ถ้ามี ComfyUI-GGUF custom-node อยู่แล้วให้ไปที่ folder tools

หลังจากนั้นให้ clone repo llama.cpp เข้ามา
git clone [https://github.com/ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp)
แล้วทำการติดตั้ง gguf
pip install llama.cpp/gguf-py
Patch llama.cpp repo (copy ทีละบรรทัด)
cd llama.cpp
git checkout tags/b3600
git apply ..\lcpp.patch
Compile llama-quantize โดยใน Windows ให้ใช้ cmake
mkdir build
cd build
cmake ..
cmake --build . --config Debug -j10 --target llama-quantize
เมื่อ compile สำเร็จแล้วจะได้ .exe แบบนี้

ขั้นตอนที่ 2 แปลง model .safetensors ให้เป็น .gguf ขนาด FP16 หรือ BF16 ก่อน (ขึ้นอยู่กับโมเดลต้นทาง)
ให้เปิด cmd ที่ folder ComfyUI-GGUF

แล้วพิมพ์คำสั่ง
python convert.py --src (ตำแหน่วงของโมเดล Flux.safetensors)
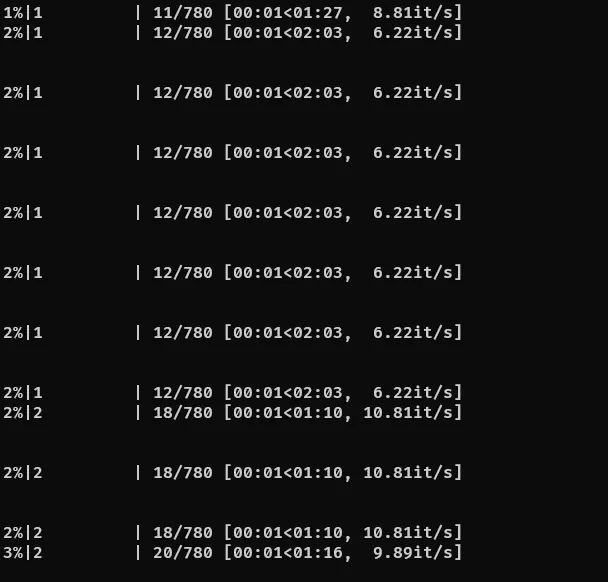
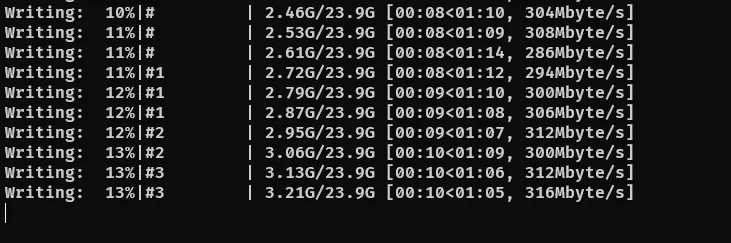
หลังจากนั้นจะเริ่มแปลงแล้วเขียนไฟล์ในตำแหน่งที่เรียกไฟล์นั้นจนเสร็จ

ขั้นตอนที่ 3 นำโมเดล .gguf ที่ได้มา Quantization ด้วย llama-quantize.exe ที่ได้ Compile จากขั้นตอนที่ 1
โดยต่อจากขั้นตอนที่สองสามารถเรียกโปรแกรมได้ตามนี้หรือว่าไปที่ Folder llama.cpp\build\bin\Debug\ ก็ได้เช่นกัน
llama-quantize.exe (ตำแหน่งของ.gguf ขนาดเต็ม) (ตำแหน่งไฟล์ที่แปลง.gguf ขนาดย่อ) ขนาดที่ต้องการจะย่อ
ขนาดที่ Model Flux ย่อได้มีดังนี้
Q2_K
Q3_K_S
Q4_0
Q4_1
Q4_K_S
Q5_0
Q5_1
Q5_K_S
Q6_K
Q8_0
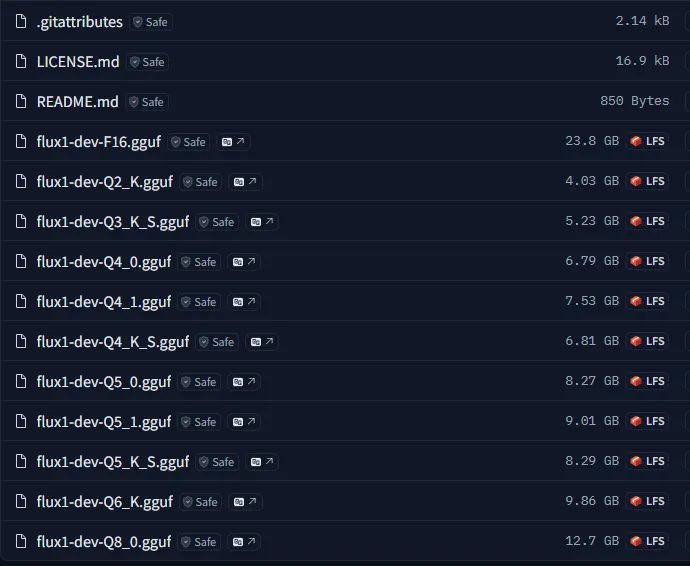
ซึ่งสามารถดูขนาดไฟล์ที่ได้จาก https://huggingface.co/city96/FLUX.1-dev-gguf/tree/main
ความเหมาะสมของแต่ละขนาดที่ทำการ Quantization
- VRAM 6 GB ใช้ Q2_K
- VRAM 8 GB ใช้ Q3_K_S
- VRAM 12 GB ใช้ Q4_K_S อาจได้ถึง Q6
- VRAM 16 GB (แนะนำให้ใช้ fp8 ไปเลย)
- VRAM 24 GB (แนะนำให้ใช้ fp8 ไปเลย)
ต้องรวม T5XXL , Clip-L และ ae ด้วยในการคำนวณ VRAM ที่ใช้คร่าวๆ
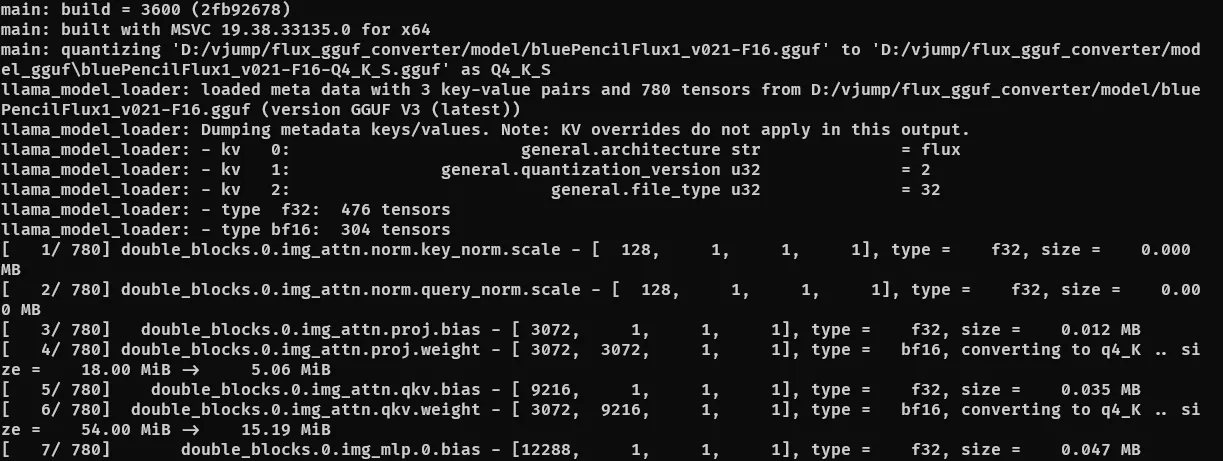
เมื่อทำการแปลงแล้วจะได้ผลลัพธ์เป็นดังนี้

จะเห็นว่าจาก F16 -> Q4_K_S ขนาดไฟล์ลดลงไปเยอะมาก ทำให้สามารถใช้ในการ์ดจอ vram น้อยได้
ขั้นตอนที่ 4 นำ model ggufไปใช้
- ComfyUI ใส่ไปที่ folder models/unet
- WebUI Forge ใส่ไปที่ models/stable-diffusion/
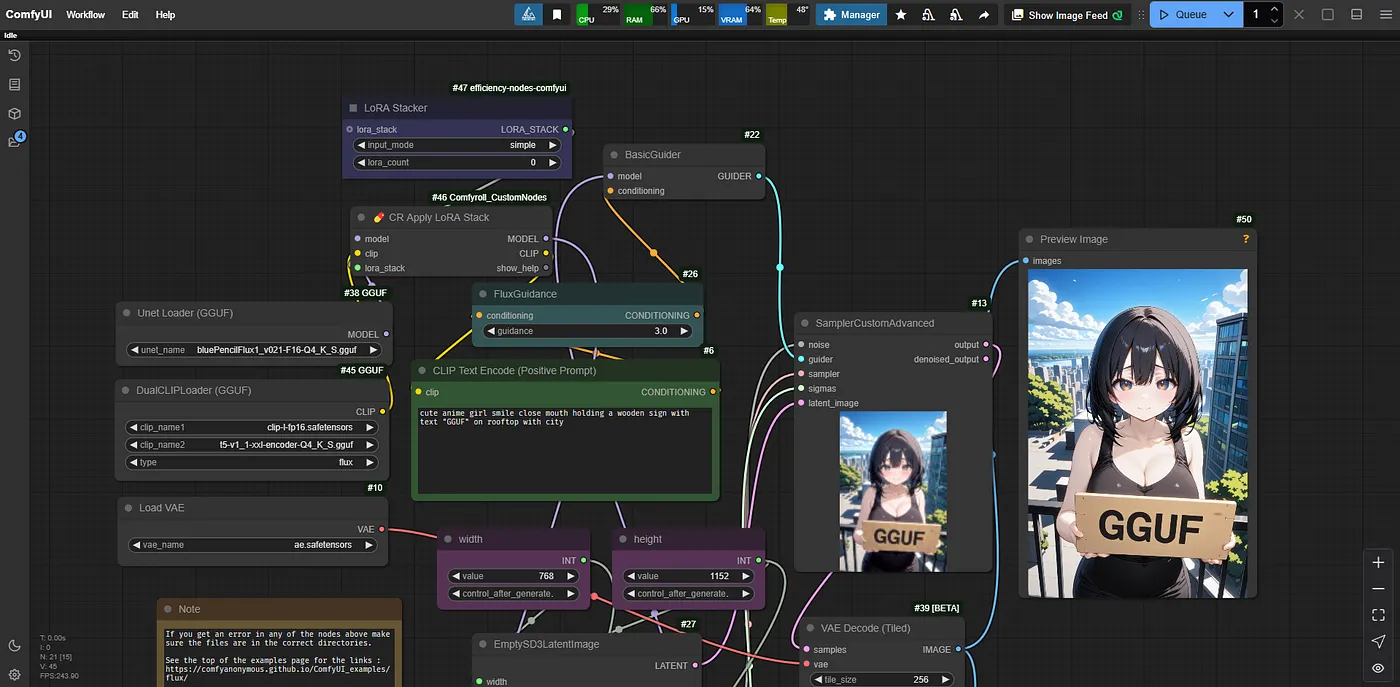
สรุป ข้อดีของ Flux GGUF
- ขนาดไฟล์เล็กลงทำให้ใช้ในการ์ดจอที่ vram ต่ำได้
- ใช้งาน LoRA ได้เหมือน Flux ปกติ
ข้อเสีย
- แปลงยาก หากต้องการทำด้วยตนเอง
- ความเร็วในการประมวลผลช้าลงเมื่อเทียบกับการ์ดจอที่ vram สูง
สิ่งที่ผู้เขียนฝากไว้ก่อนจบบทความนี้
- รอให้มีการปล่อย .exe หรือวิธีการที่ง่ายกว่านี้ในอนาคต
- โปรแกรมหน้า GUI ที่แยกออกมาจาก custom node ComfyUI-GGUF อีกทีหนึ่ง
link repo สำหรับใครอยากลอง (ทำ GUI ไว้ใช้เอง) https://github.com/vjumpkung/flux_gguf_converter_gui (กด setup.bat -> run-gui.bat เพื่อใช้งาน)

ฝากไว้เท่านี้ก่อนนะครับ ไว้ครั้งหน้าเจอกันว่าจะเป็นบทความเรื่องอะไร ก็ติดตามได้นะครับ ขอบคุณครับ 🙏
แจ้งปัญหา
