HiDream-I1 Series Open Source Text 2 Image Model ที่ดีกว่า Flux.1 Series

HiDream-I1 เป็นโมเดลที่สร้างโดย HiDream-ai โดยเป็นบริษัทจากจีน โดยโมเดลนี้มีขนาดใหญ่กว่า Flux (HiDream 18 พันล้าน parameters > Flux 12 พันล้าน parameters) และใช้ Text Encoder ถึง 4 ตัวเพื่อให้มีความตรง Prompt มากที่สุดโดยมีการใช้งาน Llama ด้วย ทำให้เข้าใจ prompt ที่พิมพ์ไปมากขึ้นและยังใช้ DiT ที่ทำให้ได้ภาพที่ดีขึ้น แต่แลกกับความเร็วในการเจนภาพที่ช้าลง การ prompt คือสามารถใช้แบบเดียวกันแบบ Flux ได้เลย
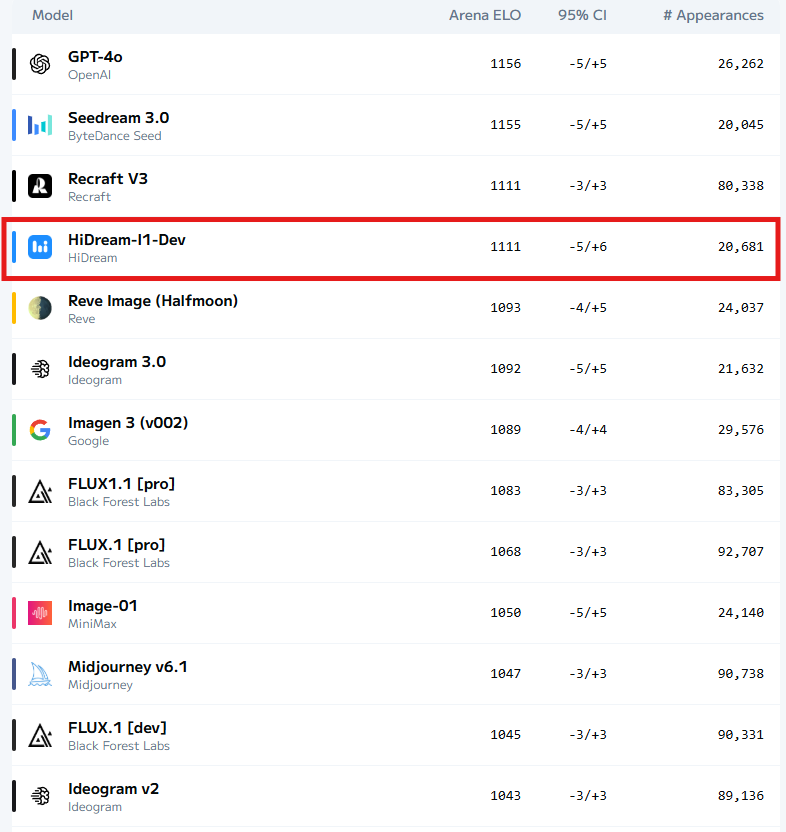
โมเดลนี้มี elo score ชนะโมเดล Open Source ทั้งหมด และแพ้แค่ Recraft V3, Seedream 3.0 และ ChatGPT ที่เป็น closed source ที่ไม่มีให้ download สามารถเล่น elo score ได้ที่นี่ https://huggingface.co/spaces/ArtificialAnalysis/Text-to-Image-Leaderboard
บทความนี้จะแบ่งออกเป็น 3 ส่วน ดังนี้
- ประเภทของ MODEL HiDream-I1
- วิธีการใช้งานเบื้องต้นผ่าน ComfyUI
- ตัวอย่างภาพ + Prompt
ประเภทของ MODEL HiDream-I1
HiDream-I1 Full
โมเดลนี้ถ้าเรียกง่ายๆ คือเป็นโมเดลขนาดเต็มดิบๆ ไม่ได้มีการบีบอัดหรือลดทอนใดๆ ซึ่งใช้เวลานานที่สุดในการเจนภาพออกมา โดยโมเดลนี้จะสามารถใช้งาน negative prompt ได้ และปรับ CFG scale ได้
วิธีการใช้งาน + การตั้งค่า เบื้องต้น
-
steps 50
-
cfg 5
-
sampler euler หรือ uni_pc
-
scheduler simple
HiDream-I1 Dev
โมเดลนี้จะเป็นการ Distrilled Model จาก HiDream-I1 Full โดยเน้นการเจนภาพที่ไวขึ้นประมาณ 2 เท่าของ Full Model และลดจำนวน steps ด้วย แต่จะทำให้ไม่มี negative prompt ซึ่งอาจเกิดสิ่งที่ไม่จำเป็นขึ้นมาได้ แต่เกิดขึ้นได้ยาก
วิธีการใช้งาน + การตั้งค่า เบื้องต้น
-
steps 28
-
cfg 1 (negative prompt ไม่ทำงาน)
-
sampler lcm
-
scheduler normal
HiDream-I1 Fast
โมเดลนี้จะเป็นการ Distrilled Model จาก HiDream-I1 Full โดยเน้นการเจนภาพที่ไวขึ้นประมาณ 2 เท่าของ Full Model และลดจำนวน steps ด้วย แต่จะทำให้ไม่มี negative prompt ซึ่งอาจเกิดสิ่งที่ไม่จำเป็นขึ้นมาได้ แต่เกิดขึ้นได้ยาก
โดยโมเดลนี้คือแทบจะเหมือนกับ Dev แต่ใช้ stpes น้อยกว่ามากๆ
วิธีการใช้งาน + การตั้งค่า เบื้องต้น
-
steps 16
-
cfg 1 (negative prompt ไม่ทำงาน)
-
sampler lcm
-
scheduler normal
เปรียบเทียบระหว่าง Full vs Dev vs Fast

ถ้าอยากลองเทียบกับ Flux
สามารถลองเทียบได้จาก huggingface spaces นี้
prompt
A stunning young Asian woman with long, flowing black hair and delicate features, wearing a traditional red kimono with golden embroidery. She stands gracefully beneath a canopy of blooming cherry blossoms, petals gently falling around her. The soft golden glow of the late afternoon sun filters through the branches, casting a dreamy ambiance. The background features a serene Japanese garden with a koi pond and a wooden bridge. Her expression is calm and poised, gazing into the distance. Shot with a medium close-up, cinematic depth of field, soft-focus background, and natural lighting.
วิธีการใช้งานเบื้องต้นผ่าน ComfyUI
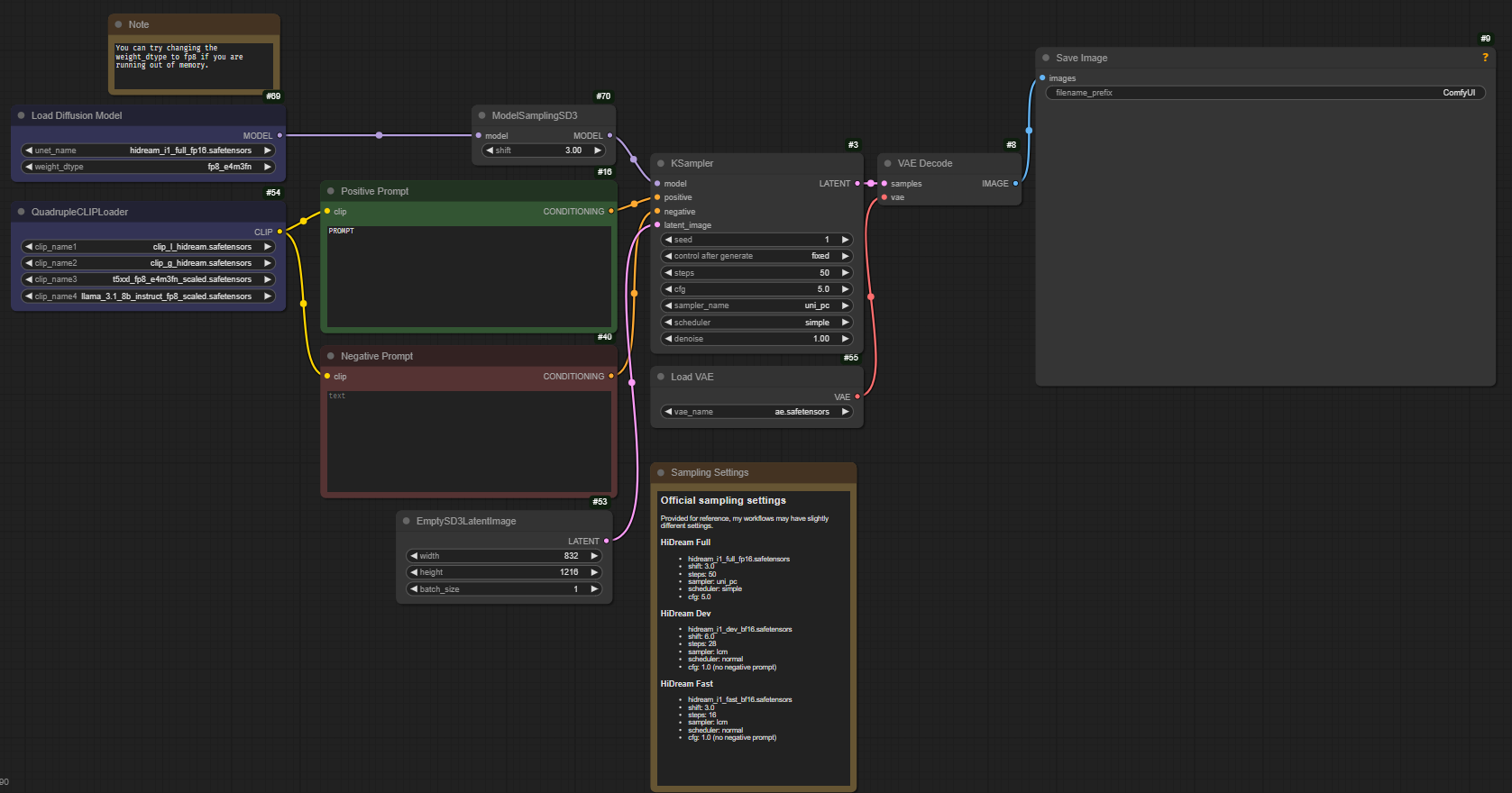
สามารถ download workflow จาก https://comfyanonymous.github.io/ComfyUI_examples/hidream/ โดยลากรูปภาพไปที่ ComfyUI ได้เลย
VRAM จากที่ทดสอบเจนภาพโดยใช้โมเดล fp8 ขนาดภาพ 1k (1024x1024) กิน vram ประมาณ 31.5 GB
ถ้าอยากใช้งานบน Runpod
ตอนนี้ใน runpod comfyui template ผมเพิ่มตัวของ HiDream-I1 ให้ใช้งานแล้วนะครับ โดยแนะนำให้เลือกการ์ดจอ Nvidia A40 และ link template นี้
-
Template url : https://runpod.io/console/deploy?template=7crlm3hxud&ref=6h6f9kga (ให้กดลิ้งนี้)
สิ่งที่ต้อง download
Text Encoder
Diffusion Model (Unet) ขนาด fp16/bf16
Text Encoder แบบ GGUF สำหรับ VRAM น้อยกว่า 32 GB
Diffusion Model แบบ GGUF สำหรับ VRAM น้อยกว่า 32 GB
Model ขนาดเท่าไหร่ถึงจะเหมาะสมสำหรับโมเดลนี้
| size | vram |
|---|---|
| fp16 | 80GB |
| fp8 | 32GB |
| gguf q6 | 24GB |
| gguf q5 | 24GB |
| gguf q4 | 24GB |
| gguf q3 | 16GB |
| gguf q2 | 12GB |
ถ้าเป็น gguf ให้คิดคร่าว ๆ โดยนำขนาดไฟล์ของ diffusion model + text encoder 4 ตัว และเผื่อไว้สัก 2 GB สำหรับการเจนภาพ
เกร็ดความรู้จากที่เจอใน X/Twitter

- การเจนภาพใช้แค่ llama3 เป็น text encoder ตัวเดียวในการเจนภาพ ก็เพียงพอแล้ว
cr. https://x.com/ostrisai/status/1909415316171477110
ตัวอย่างภาพ + Prompt
ภาพตัวอย่างนี้จะคละกันทั้ง 3 โมเดล (Full Dev Fast)

prompt
anime screencap, anime girl with massive fennec ears and a big fluffy fox tail with
long wavy blonde hair and blue eyes wearing a pink sweater a large oversized black winter
coat and a long blue maxi skirt and large winter boots and a red scarf and large gloves
sitting in a sled sledding fast down a snow mountain
with white text overlay side of character with bold font "HiDream I1 Full"

prompt
pvc toy figure, japanese anime girl character, blue cute mahou shojo dress

prompt
a photograph of a wall in the backrooms, uncanny,
liminal space, the text "HIDREAM FAST" is spray-painted on the wall

prompt
Three transparent glass bottles on a wooden table. The one on the left has red liquid and the number 1. The one in the middle has blue liquid and the number 2. The one on the right has green liquid and the number 3.

prompt
Epic anime artwork of a wizard atop a mountain at night casting a cosmic spell
into the dark sky that says "HiDream I1" made out of colorful energy

prompt
5 girls standing at the city with following these
1. Red shirt blue jeans
2. White shirt black short
3. blue shirt green skirt
4. black suit, white shirt, pink skirt,
5. pink shirt , white jeans

prompt
Eva and Adamo Lego figures, positioned in a vibrant, whimsical garden setting,
surrounded by lush green foliage and colorful flowers, with a serene sky and a
majestic tree in the background, capturing the innocence and wonder of the Garden of Eden

prompt
A fit and athletic Asian man with sun-kissed skin, short wavy hair, and a confident smirk,
wearing an unbuttoned white linen shirt over board shorts. He holds a surfboard under his arm,
standing on a golden sandy beach with the ocean waves behind him. The setting sun casts a warm
orange and pink glow across the sky, reflecting on the water. His toned physique is accentuated
by the soft lighting. Dynamic wide shot, warm golden-hour lighting, relaxed and adventurous atmosphere,
beach lifestyle aesthetic.

prompt
Thai taxi car with color green yellow wrap driving on a thai urban street.

prompt
a sleek, modern logo design featuring the brand name "VJUMPKUNG", bold sans-serif
typography with futuristic and minimalistic aesthetics, sharp clean lines with subtle curves,
monochrome or limited color palette (black, white, and electric blue), optional geometric icon
integrated with the text, suitable for a high-tech or digital brand, vector-style design on a flat
white or gradient background, strong visual identity, scalable and professional appearance

prompt
cute anime girl with massive fluffy fennec ears and a big fluffy tail blonde messy long hair
blue eyes wearing a maid outfit with a long black gold leaf pattern dress and a white apron
mouth open holding a fancy black forest cake with candles on top in the kitchen of an old dark
Victorian mansion lit by candlelight with a bright window to the foggy forest and very expensive
stuff everywhere
ภาพอื่นๆ

ข้อจำกัดที่เจอในบาง prompt

-
style บางแบบทำภาพออกมาไม่ได้ เช่น ติดโทนสีแปลกๆ หรือตัวอักษรเพี้ยนไม่ตรง prompt หรือการทำภาพ NSFW ซึ่งไม่สามารถทำได้
-
ระวังภาพติดลายน้ำ โดยมีคนเริ่มเจอว่าได้ภาพติดลายน้ำแบบเป๊ะๆ จากภาพ stock เว็บแหน่งหนึ่งด้วย ถ้าใช้ model Full negative prompt เข้าไปได้
สรุปเบื้องต้นของโมเดลนี้
โดยรวมถือว่าเป็นโมเดลหนึ่งที่ออกมาดีในระดับนึงที่ปล่อยให้ download และ open source ที่สามารถ Fine Tuned ต่อได้ในอนาคต แต่ก็แลกกับว่ากินสเปคที่สูงขึ้นเรื่อย ๆ ทำให้การ์ดจอที่มีอยู่อาจจะไม่เพียงพอ โดยเฉพาะการ Fine Tuned คือทำได้ยากขึ้นมากในการใช้งานกับคอมที่บ้าน ต้องเช่าการ์ดจอบน Runpod เอา ถึงจะใช้งานได้ และผู้เขียนคิดว่าอนาคตของ Text To Image คงต้องเดินทางด้วยแนวทางนี้ เหมือนกับ chatGPT-4o ออกมาล่าสุด
แถม

HiDream-E1 https://github.com/HiDream-ai/HiDream-E1 จะเป็นโมเดลที่คุยเหมือน chatgpt-4o ได้ต่อเนื่อง และอาจมีการ open source เร็วๆ นี้
