Illustrious-XL โมเดลที่มาแรงในสาย Anime ณ ตอนนี้

หลายๆ คนน่าจะเห็นใน CivitAI ว่ามีประเภทของโมเดลใหม่ นอกเหนือจาก SD1.5, SDXL, Flux.1 Dev, Pony หรืออื่นๆ และก็มี illustrious ขึ้นมาให้เห็นขึ้นมาได้สักพักแล้ว วันนี้จะมาดูว่า Model นี้ใครเป็นคนสร้าง แล้วทำไมการทำ model สุดทางใดทางหนึ่ง อาจจะดีกว่า โมเดลที่ทำได้ทุกอย่างแต่ไม่สุดสักอย่างในขนาดที่จำกัดก็เป็นได้
Illustrious ถูกสร้างโดย Onoma AI Research เป็นการนำ dataset จาก danbooru2023 มาเทรนเป็นจำนวน 7.5 ล้านรูปโดยใช้ caption เดิมๆ เทรนด้วยความละเอียด 1024x1024 และมี prompt style เป็น tags และก็มีการจัดเรียง tags ใหม่ พร้อมกับ การคัดคุณภาพ ซึ่งใช้คำเดียวกันกับสมัยโมเดล SD1.5 ต่างๆ ทำให้การ prompt ทำได้ง่ายกว่า Pony ที่ต้องใช้ score_9, score_8_up ในการกำหนดคุณภาพแทน อาจจะให้ความรู้สึกเหมือนย้อนเวลาไปในสมัย SD 1.5 ได้
การจัดเรียง Prompt ของโมเดลนี้ในตอนเทรน
person count ||| character names ||| rating ||| general tags ||| style ||| score range based rating ||| year modifier
การ prompt จะใช้ตัว comma , ในการคั่นระหว่างแต่ละ tags ซึ่งเป็นวิธีที่คุ้นเคยที่ทำกันในโมเดลสาย 2D Anime ที่ผ่านมา
ตัวอย่าง Prompt
- การใช้จริงสามารถสลับได้ เพราะว่าการเทรนโมเดลมีการสลับ caption เรื่อยๆ
1girl, solo, character_name, safe, anime screencap, ใส่ tags เกี่ยวกับภาพที่ต้องการ, masterpiece, best quality, newest
Negative Prompt
bad quality,worst quality,worst detail,sketch,censor, และสิ่งที่ไม่ต้องการ
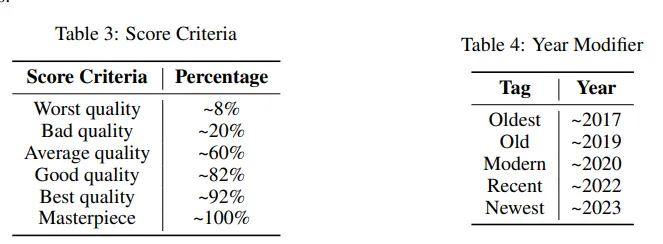
Prompt คุณภาพ (score range based rating)และ ปี (year modifier)
การตั้งค่าสำหรับโมเดล v0.1 นี้ (อ้างอิงจาก paper)
- steps มากกว่า 20
- CFG 5-7.5
- euler a (sampler) normal (scheduler)
- ความละเอียดประมาณ 1 MP เช่น 1024 x 1024, 832 x 1216 หรือความละเอียด SDXL ทั่วไป
จุดเด่นของโมเดลนี้
- รู้จักตัวละครเยอะมากๆ มากกว่า animagineXL, Pony อีก แต่ก็ขึ้นอยู่กับความนิยมของตัวละครนั้นๆ ด้วย ที่ดังๆ มีหมดเลย ถึงปี 2023
- สร้าง style ที่ออกมาได้หลากหลายมาก เช่น ภาพมืดสุด ภาพสว่างสุด
- มีขนาดที่เหมาะสมเนื่องจาก เป็นการ Fine-Tuned ต่อจาก SDXL ทำให้สามารถใช้ได้กับการ์ดจอที่ไม่จำเป็นต้องมี VRAM เยอะมากได้ (8GB ขึ้นไปก็สามารถเจนได้แล้ว)
- มีความเข้าใจ prompt ถือว่าในระดับที่โอเคระดับหนึ่ง ถึงจะไม่ถึงระดับ Flux.1 ที่มี T5XXL แต่ก็สามารถรับ Prompt tags ยาวๆ ได้
- เทรน LoRA ผลลัพธ์อาจออกมาดีกว่า Pony, SDXL
จุดอ่อนของโมเดลนี้
- ตัว base model หากไม่ระบุ style เข้าไป ภาพที่ได้จะออกมาเป็นการสุ่มมากๆ ทำให้คุมคุณภาพได้ยาก
- LoRA ที่เทรนจาก Pony, SDXL ส่วนมากใช้ไม่ได้ ทำให้ต้อง Train LoRA ใหม่ และ การตั้ง parameters แตกต่างเล็กน้อยด้วย
ข้อจำกัดจากที่ผู้พัฒนาได้กล่าวไว้
- โมเดลอาจจะไม่ได้เข้าใจฉากที่มีความซับซ้อน เพราะว่าเป็นการใช้ tag ในการ prompt แต่ละภาพขึ้นมา ซึ่งอาจจะทำได้ยากในโมเดลนี้
- โมเดล ยังคงไม่ค่อยเก่งในเรื่องของการทำข้อความบนภาพ เนื่องจาก caption ที่เทรนไม่ได้มีการบอกข้อความโดยตรง
สิ่งที่เกิดขึ้นหลังจาก Model นี้ถูกปล่อยออกมา
- CivitAI ตั้งหมวดใหม่ขึ้นมาเลย เหมือนกับ Pony
- Checkpoint Merge หลายๆ ตัวเริ่มมาทำให้กับ Illustrious มากขึ้น ทำให้ได้โมเดลที่ต่อยอดออกมาที่มีคุณภาพที่ดี และ style นิ่งๆ ออกมาได้
- LoRA เริ่มผุดเป็นดอกเห็ด ทำให้มีให้เล่นมากมาย ทั้ง character, style, concept
โมเดลนี้เป็น 1 ในโมเดลที่มาแรงในระดับหนึ่งและเป็นกระแสสำหรับการทำภาพ anime เลย ซึ่งปัจจุบันมี NoobAI อีกตัวแต่ว่า ยังไม่ค่อยชัดเจนในเรื่องการทำ LoRA และ ความยากในการใช้งาน ทำให้ Illustrious เข้าถึงง่ายกว่า
Reference
