คู่มือการ Train LoRA สำหรับ Stable Diffusion ด้วย kohya_ss

คู่มือนี้เหมาะสำหรับคนที่ต้องการเจาะลึกว่าการทำงานของการ Fine-Tuned Stable Diffusion Model ด้วยการทำ LoRA ขึ้นมา โดยการทำคู่มือนี้จะเน้นไปที่การเจาะลึก แต่ละส่วนให้เข้าใจแต่ละอย่างมากขึ้น เพื่อให้เกิดความสมบูรณ์มากขึ้น รวมทั้งประสบการณ์ที่เริ่มได้นำ LoRA ลง CivitAI แล้วด้วย
- เครื่องมือในการเทรนเน้นไปที่ kohya-ss GUI v24.3.0 FORKED by vjumpkung โดยเป็น version ปรับแต่งจาก kohya-ss GUI ของคุณ bmaltais โดยเน้นไปที่การแก้ UI บางส่วนให้สมบูรณ์และแก้บัคที่เกิดจาก dependencies ที่ยังไม่ถูกแก้จากต้นทาง
- หากต้องการอ่าน version เรียบเรียงที่ให้เข้าใจง่ายแล้ว อ่านได้จาก ขั้นตอนการ Train LoRA สำหรับ Stable Diffusion ฉบับสมบูรณ์ โดยผู้เขียนเอง
รีวิว kohya-ss GUI v24.3.0 FORKED by vjumpkung
- ปรับแต่งเพิ่มเติมจาก kohya-ss GUI ของคุณ bmaltais
- แก้ไขปัญหาจำนวน module ของ text encoder หายไป ทำให้จำนวน parameters ของ LoRA ในส่วนของ Text Encoder หายไป 50% (แก้โดยเปลี่ยน version ของ transformers)
- แก้ไข UI ให้มีโทนสีที่สอดคล้องกันให้มากขึ้น
- เพิ่ม scheduler และ optimizer ที่ kohya-ss/sd-scripts รองรับล่าสุด
- รองรับ python 3.10.x 3.11.x และ 3.12.x
- รองรับการเทรน LoRA สำหรับ SD1.5, SDXL (Pony), SD3 (Large and Medium), Flux.1 Dev
- link วิธีการติดตั้งโปรแกรม (coming soon) ซึ่งการติดตั้งเหมือนกับ kohya-ss GUI เดิมๆ ทำได้ง่ายและสะดวกเหมือนเดิม
Overview ภาพรวมของเนื้อหาทั้งหมด
ก่อนที่จะเจาะลึกไปในแต่ละส่วนผมจะให้ดูภาพรวมก่อนว่าการเทรน LoRA มีขั้นตอนอะไรบ้าง เพื่อให้ผู้อ่านได้ทำความเข้าใจแต่ละส่วนได้ คลิ๊กที่หัวข้อเพื่อกดข้ามไปยังขั้นตอนที่ต้องการอ่าน
- เตรียม Dataset รูปภาพสำหรับการเทรน โดยมีการ pre-process ข้อมูลก่อน
- Caption dataset เพื่ออธิบายรูปให้ Pre-Trained Model (checkpoint) เข้าใจ
- การตั้ง Parameters ต่างๆ เพื่อให้โมเดลเรียนรู้ให้มีประสิทธิภาพมากที่สุด
- การตรวจสอบ LoRA ผ่านเครื่องมือ inspector ต่างๆ
- การ Resize LoRA เพื่อให้ LoRA มีขนาดเล็กลงเพื่อประหยัดพื้นที่ และทำให้โหลดเร็วขึ้น
1. เตรียม Dataset รูปภาพสำหรับการเทรน
สิ่งที่ต้องการ
- รูปภาพสกุล jpg, png หรือ webp
- ขนาดเท่าไหร่ก็ได้ แต่ถ้าแนะนำให้มีความละเอียด 512x512 pixels ขึ้นไป
แนวทางคร่าวๆ ในการทำ dataset
Character Dataset
- รูปให้มีจุดเด่นของตัวละคร ให้ชัดเจน ครึ่งตัว เต็มตัว หันหน้าในแต่ละด้านที่หลากหลาย และ background หลายๆ แบบ จะช่วยทำให้การ Train เข้าใจได้ว่าสิ่งนี้คือตัวละครจริงๆ
- ควรกระจายมุมของภาพให้ได้จำนวนที่ใกล้เคียงมากที่สุดเพื่อป้องกันความ Bias ของ LoRA ไปในทางใดทางหนึ่ง
Style Dataset
- หาภาพที่หลากหลายที่สุดเท่าที่เป็นไปได้ แต่ให้อยู่ใน style เดียวกัน
- หลีกเลี่ยงการนำภาพที่มีตัวละครซ้ำ เพราะว่าจะทำให้ LoRA เข้าใจว่าตัวละครนั้นคือ Style ของภาพด้วย
- รูปต้องมีเยอะมากๆ จะช่วยทำให้สร้าง style ได้ง่ายขึ้น (50++ รูป)
Face Dataset
- ครอปบริเวณภาพให้เหลือช่วงไหล่ขึ้นไป
- หากต้องการหุ่นด้วยให้แยก ครึ่งตัวและเต็มตัวไว้ด้วย แต่ให้ระวังเรื่องของการซ้ำกันของชุดเพราะว่า หากทำแล้ว LoRA จะเข้าใจผิดเป็นตัวละครได้
Concept Dataset เช่น กางเกง ท่าทาง สิ่งของ หรืออื่นๆ
- หาภาพที่ทำในสิ่งที่เป็น concept เดียวกัน โดยให้มีความหลากหลายของสิ่งอื่น ๆ นอกเหนือ concept แต่การ Train Concept LoRA อาจทำให้มีการติดสิ่งอื่นเข้าไปด้วย เช่น รูปแบบของคนกับ concept, หน้าคน, ตัวละคร
จำนวนรูปภาพ
- แนะนำว่า รูปภาพที่ดีย่อมดีกว่ารูปภาพที่เยอะ ควร balance ตัว dataset ให้สิ่งที่ต้องการร่วมกันได้
- แนะนำง่ายๆ คือ 20 รูปขึ้นไปถึงจะโอเค ทำให้จัดการ parameters ง่ายขึ้น
- หากรูปภาพ background ไม่หลากหลาย หรือ รูปน้อยระดับ 1–10 รูป ในจุดนี้ การปรับ parameters ช่วยได้ เช่น alpha mask, multires noise
ขั้นตอนการ Pre-Process รูปภาพ
- คัดแยกรูปภาพ โดยใช้กับ dataset ตัวละคร เพื่อแยกชุดแต่ละแบบโดยจะนำไปใช้กับการคำนวณ repeat พร้อมกัน
- ถ้ามีการ crop รูป ซึ่งปัจจุบันไม่ต้องครอปเป็น 1:1 (สี่เหลี่ยมจตุรัสแล้ว) แต่ระวังเรื่องของการ crop มากเกินไป แนะนำให้ crop เป็นอัตราส่วนปกติเช่น 4:3, 3:2, 5:4, 16:9 เป็นต้นเพราะว่า หากไม่ได้ทำตามนั้น bucket resolution จะครอปให้อีกครั้งหนึ่งทำให้องค์ประกอบบางส่วนของภาพหายไปได้ และไม่ตรงกับ caption (โอกาสน้อย)
สิ่งที่หลีกเลี่ยงในการทำ Dataset
- การ crop รูปมากเกินไปเช่น dataset กางเกง ทำ dataset โดยการ crop เหลือแค่กางเกง สิ่งที่อาจทำให้ LoRA overfitting ได้คือ ออกมามีแต่กางเกง ไม่เห็นตัวและหัว ก็เป็นไปได้ (เกิดขึ้นเฉพาะ SD1.5)
- การนำภาพที่มีความคล้ายมากๆ เช่น รูปที่มีหันข้างอย่างเดียว, รูปคนใส่กางเกงที่มีนางแบบเดียว
2. Caption dataset เพื่ออธิบายรูป
เครื่องมือในการ caption รูปภาพ เช่น BLIP, joy caption, LLaVA, ChatGPT (LLM ออนไลน์), florence2, wd14 tagger เป็นต้นโดยการทำ caption จะมีอยู่ 2 รูปแบบได้แก่
-
- tag based caption (เป็นคำคั่นด้วย comma) เหมาะสำหรับ SD1.5, SDXL, Pony, IllustriousXL เป็นต้น
ตัวอย่าง
triggerword, 1girl, solo, long hair, looking at viewer,
blush, simple background, white background, gloves,
hat, dress, upper body, pink hair, multicolored hair,
horns, tongue, white gloves, tongue out, gradient hair,
red headwear, red dress, white footwear, fur trim, christmas
-
- natual language caption (แบบบรรยาย) เหมาะสำหรับ SDXL, Flux1 Dev, SD3, SD3.5 Large (Medium)
ตัวอย่าง
triggerword, A photo-realistic shoot from a frontal camera angle about a
young man smiling while wearing a floral patterned jacket and a white shirt,
standing in front of a red textured background. on the middle of the image,
a 20-year-old man appears to be smiling, looking directly at the camera,
with a bright and even smile. he has dark hair styled in a short,
slicked back manner, and is wearing a white jacket with a black and
white checkered collar and a patterned shirt underneath. the jacket
has a floral print, and he is standing in a relaxed pose, with his hands
resting on his lapels. the background is a red, textured wall with a subtle
pattern, and the lighting is soft and even, creating a warm and inviting
atmosphere.
- หมายเหตุ การทำ natural language caption อาจทำให้การจัดการ caption ที่ไม่ต้องการออกได้ยาก เนื่องจากเป็นการบรรยายด้วยภาษาแล้ว
- Trigger Word สำคัญเสมอ และ ไม่ควรซ้ำกันกับ checkpoint ด้วย
ข้อควรระวังในการทำ caption (เฉพาะ tag based caption)
- คำที่ใช้ต้องสอดคล้องกับ รูปภาพ และควรตรวจสอบคำที่ใช้ใน checkpoint ว่ารู้จักหรือไม่
- SD1.5, SDXL, Pony, IllustriousXL มี CLIP ที่ไม่ได้เก่งมาก ซึ่งคำที่คล้ายกันอาจทำให้ภาพออกมาปนมั่วกันได้ หากเป็นรายละเอียดเล็กๆ
- Flux, SD3.5 มี T5XXL ซึ่งเข้าใจแต่ละคำได้มากขึ้น ซึ่งช่วยทำให้การทำ caption ง่ายขึ้น
รีวิวเครื่องมือ + model caption แต่ละตัว
- TAGGUI เป็นเครื่องมือที่เหมาะสำหรับ tag based เพราะว่าสามารถจัดการ tag ได้ง่ายๆ เช่น ลบ เพิ่ม ทีละหลายๆ รูปได้ และดูจำนวนของ tag ที่เกิดขึ้นใน dataset ทั้งหมดได้ แถมมี model caption สำหรับให้บรรยายรูปภาพได้เลย
- Joy Caption ตัวนี้ใช้ LLM ในการบรรยายรูปภาพ ซึ่งให้ความยาวของ caption ในระดับที่ยาวและเป็น natual language caption บรรยายด้วย แต่ใช้ทรัพยากรการ์ดจอเยอะ (VRAM)
- ChatGPT และ LLM ที่อ่านรูปภาพได้ (Online) เหมาะสำหรับผู้ที่ไม่มีการ์ดจอหรือการ์ดจอไม่เพียงพอที่จะรัน LLM บนเครื่องได้ หรือต้องการความแม่นยำสูงในการ caption แต่ข้อเสียคือ จำนวนการใช้ และ นโยบายการใช้งานที่แตกต่างกันไปเช่น บรรยายรูป Sexy ไม่ได้ เป็นต้น
- florence2 โมเดล caption โดยเฉพาะจาก microsoft โดยมีขนาดเล็กทำใข้ vram ไม่ถึง 4 GB ในการทำงาน ซึ่งมีการ fine-tuned ทำให้ caption ได้ทุกรูปภาพได้ และ เลือกรูปแบบการ caption ได้ ComfyUI node, Online
- wd14 tagger เครื่องมือนี้มีใน kohya_ss ในตัว ซึ่งในปัจจุบันอาจจะไม่ได้แม่นยำมาก แต่ก็ใช้งานง่าย สะดวก รวดเร็ว สำหรับ tag based caption
- BLIP caption เครื่องมือนี้มีใน kohya_ss ในตัว ซึ่งในปัจจุบันอาจจะไม่ได้แม่นยำมาก และ ยิ่งยาวยิ่งวนเวียน เหมาะ สำหรับ natural language caption แบบสั้นๆ
*Google Colab สำหรับการนำ dataset ไปทำ caption ด้วย Florence 2 อัตโนมัติ link Google Colab
2.5 จัด Folder เพื่อสำหรับการ Train LoRA
- ในการจัด Folder โดยการตั้ง Folder จะสร้าง Folder โดยตั้งตัวเลขนำหน้า เพื่อเป็นการแทนจำนวน repeat โดยเปรียบเสมือน copy จำนวนรูปภาพ และคั่นระหว่างกลางด้วย _ และชื่อ Folder ตามที่ต้องการ
- รูปแบบข้อความ “ ตัวเลข_ชื่อFolder ”
ตัวอย่าง
**DATASET**
├───10_first_costume_cat_ears
├───10_new_year
├───15_other_costume
├───15_school
├───25_school_jacket
├───3_first_costume
├───6_casual
└───6_party_dress
เมื่อทำการจัด folder แล้วก็สามารถย้ายรูปภาพพร้อม caption เข้าไปได้ โดยการแยก folder ช่วยในการปรับจำนวน repeat ให้ไม่เท่ากันได้ และ
- อีกรูปแบบคือใช้ dataset config toml สามารถทำได้ตามนี้ link
3. ตั้ง Parameters เพื่อให้โมเดลเรียนรู้ให้มีประสิทธิภาพมากที่สุด
3.1 accelerate
เป็นโปรแกรมที่ใช้ในการเรียกใช้ script ในการเทรน LoRA ซึ่งสามารถปรับแต่งการใช้งานการ์ดจอ การทำ mixed precision เป็นต้น โดยใน GUI จะปรับต่อไปนี้ (ในจุดหลักๆ)
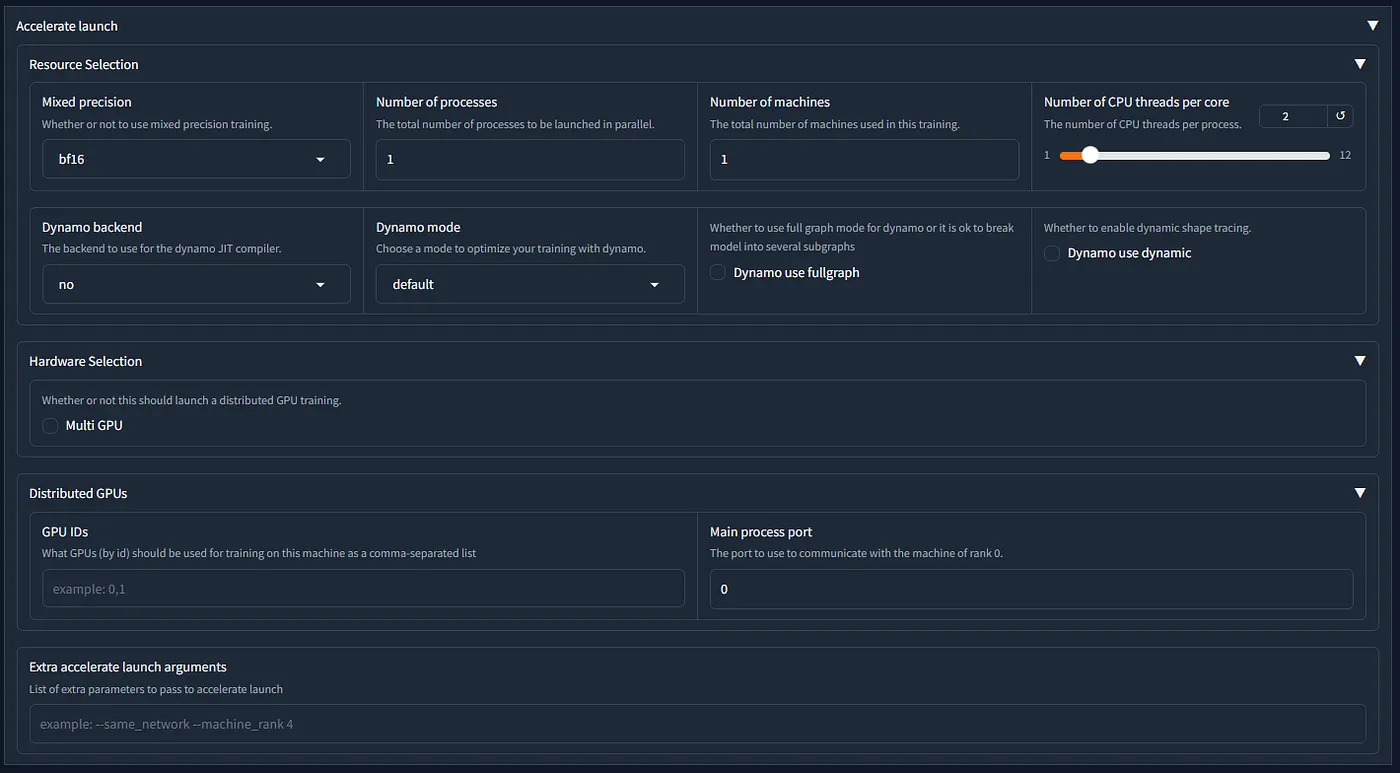
Mixed Precision

Mixed Precision ปกติจะตั้งอยู่ 2 ค่า
- fp16 ใช้กับการ์ดจอรุ่นที่เก่ากว่า RTX 3000 series , Tesla T4 (colab)
- bf16 มีความแม่นยำใกล้เคียง fp32 เพราะว่ามีค่า exponent เท่ากัน ใช้กับการ์ดจอ RTX 3000 series ขึ้นไป , Telsa L4 (colab), Tesla A100 (colab)
Number of CPU threads per core

- ดูจาก CPU ว่ามี 1 core กี่ thread (ปัจจุบันแทบจะ 2 thread หมดแล้ว) แล้วเอาจำนวน threads มาตั้ง (เช่น Intel i5 12400F มี 6 core 12 threads → 2 threads per core)
3.2 Model
เป็น part ที่เลือก checkpoint, output folder, dataset และ ตั้งชื่อไฟล์ LoRA
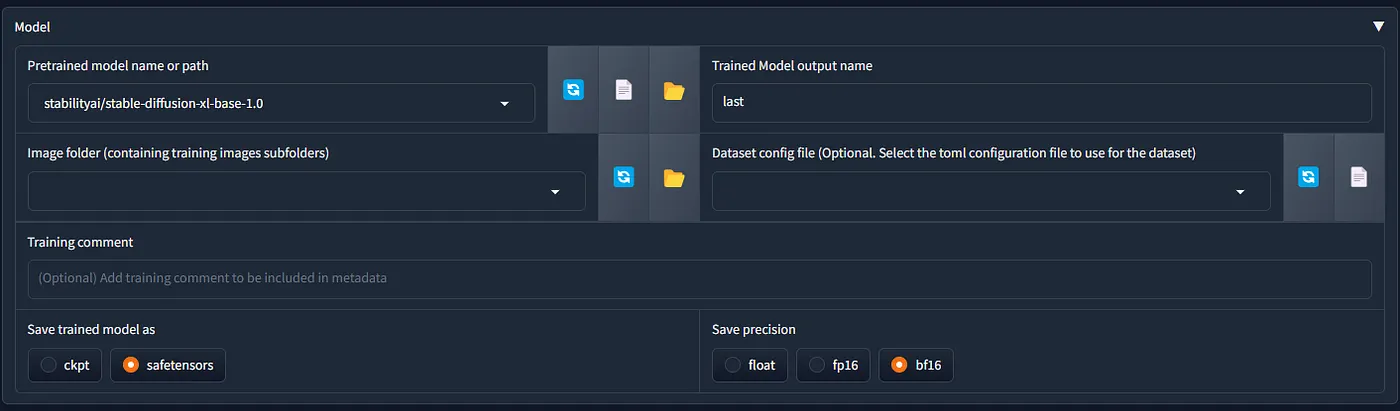
Pretrained model

- ให้เลือก checkpoint โดยจะมีการตรวจสอบอัตโนมัติว่าเป็น model ประเภทอะไร (SD1.5 ,SDXL, SD3, Flux.1 เป็นต้น)
- การเลือก model แนะนำว่าเลือก base model เป็นหลัก แต่ใช้ fine-tuned model ก็ได้แต่ทำให้ความอิสระยืดหยุ่นของ LoRA อาจลดลงได้
Trained Model output name

- ตั้งชื่อไฟล์ LoRA ที่ save ออกมา
Image Folder

- ตำแหน่ง folder dataset
saved precision
- แนะนำให้ตั้งเป็น bf16 หากการ์ดจอรองรับ bf16 ถ้าไม่เลือก fp16
3.3 Folders

Output directory
- ตำแหน่ง folder ของ Config, ไฟล์ LoRA ที่ save
Logging directory
- เก็บ log สำหรับวิเคราะห์ความคืบหน้าของการ Train LoRA เช่นการทำงานของ Learning Rate, ค่า loss (ใช้ร่วมกับ tensorboard)
3.4 Metadata (optional)
- ใช้สำหรับใส่ข้อมูลต่างๆ
3.5 Dataset Preparation
- ใช้สำหรับการจัดการ dataset (หากไม่ได้ตั้ง folder แบบตัวเลขนำหน้า)
3.6 Parameters
ส่วน Basic — จุดหลัก ๆ ที่ปรับ LoRA พื้นฐาน

สิ่งที่ปรับในส่วนพื้นฐานจะมีดังนี้
- LoRA type — Standard สำหรับ SD1.5, SDXL (Pony), SD3 Flux.1 เลือก Flux ถึงจะเทรนได้
- Train batch size - เป็นการมองว่าแต่ละ step จะทำการคำนวณกี่ครั้ง โดยการเพิ่มจำนวน จะทำให้การทำ Gradient Update เป็นการเฉลี่ยเข้าไปแทน จากที่แต่ละส่วนได้คำนวณออกมา ถ้าตั้งเยอะขึ้นกิน VRAM เยอะขึ้น ปกติตั้งกันที่ 1–4 เปรียบเทียบง่ายสุดคือ จำนวนรถยนต์
- Epoch — คือ เป็นการบอกว่าเราจะให้ model อ่าน dataset ทั้งหมดกี่รอบ โดยในที่นี้จะเป็นการ save model ออกมาด้วยเมื่อจบแต่ละ epoch
- Max train epoch -> ปรับเป็น 0 เพื่อคำนวณอัตโนมัติแทน
- Max train steps -> ปรับเป็น 0 เพื่อคำนวณอัตโนมัติแทน
วิธีการคำนวณ steps ทั้งหมดในการเทรน = image * repeat * epochs / batch_size
สิ่งที่แนะนำให้ติ๊กถูกไว้เลย เพราะว่าช่วยในการเทรนให้เร็วขึ้น
- Cache Latents
- Cache Latents to disk อันนี้จะใช้เมื่อมีการเทรนใหม่ หรือว่าการ resume training
Learning Rate (LR)
- ใน SD1.5, SDXL จะรองรับการตั้ง Learning Rate ใน 2 จุดคือ UNet และ Text Encoder (TE)
- ใน Flux ตั้งได้ 3 จุดคือ UNet, Clip-L (TE1), T5XXL (TE3)
- โดยค่าพื้นฐาน 1e-4 เข้าไปด้วย และใช้ TE LR อยู่ที่ 25–50% ของ UNet LR หากมากกว่านี้อาจทำให้ TE Overfitting ได้ แล้วทำให้เข้าใจคำนั้นเพี้ยนไปได้
Optimizer
เป็นการเลือกว่าใช้สมการในการคำนวณ Gradient ออกมายังไง ซึ่งแต่ละตัวจะมีวิธีที่แตกต่างกันออกไป ในตัวนี้แนะนำในตัวหลักๆ ที่นิยมใช้กันและ args เพิ่มเติมที่แต่ละ optimizer ต้องการ
แบบต้องตั้ง LR Scheduler
- (แนะนำ) AdamW, AdamW8Bit 2 ตัวนี้คือพื้นฐานที่ใช้กันเลย โดยมี weight_decay ในการทำให้ทอนคะแนนทิ้งลงไปได้ เพื่อให้การทำ gradient update แต่ละครั้งน้อยลงไปได้ แต่ข้อควรระวังคือ AdamW เป็น fp32 แต่ AdamW8Bit เป็น fp8 ซึ่งตัว 8bit gradient update มีค่ามากกว่า AdamW 4 เท่าซึ่งอาจต้องลด Learning Rate ลงไปเพื่อป้องกัน Overfitting
- (แนะนำ) Prodigy ตัวนี้แนะนำสำหรับการเทรนที่ไม่เกิน 3000 steps ซึ่งใช้งานง่าย เพราะว่าไม่ต้องตั้ง Learning Rate (ปรับเป็น 1 ทั้งหมด) แต่จะเปลี่ยนไปเป็นการตั้ง d_coef แทน และมี args เพิ่มเติม คือ decouple=True weight_decay=0.01 d_coef=2 use_bias_correction=True safeguard_warmup=True
- Lion, Lion8Bit ตัวนี้ Google Brain บอกว่าดีกว่า AdamW แต่ต้องลด Learning Rate 3–10 เท่าจากเดิม เพราะว่า gradient ที่เข้าไปยังตัว model เยอะกว่า AdamW
- AdEMAMix, AdEMAMix8Bit เป็นการเพิ่มขั้นตอนการคำนวณเพิ่มจาก AdamW ขึ้นมาโดยมี beta3 เข้ามาเป็น args พิเศษ แต่ตัวนี้มีข้อเสียคือเทรนช้าลง แต่อาจได้คุณภาพที่ดีขึ้นได้
- AdaFactor ตั้ง optimizer args ต่อไปนี้ relative_step=True scale_parameter=True warmup_init=True โดยตัวนี้ตั้งแค่ Learning Rate และใช้ LR scheduler เป็น constant
แบบไม่ต้องตั้ง LR Scheduler (ScheduleFree)
- AdamWScheduleFree ตัวนี้เหมือน AdamW ทุกอย่างยกเว้น LR schedule ไม่มีผล เพราะว่า ปรับให้เองได้ ซึ่งอาจต้องเพิ่ม Learning Rate เข้าไปแทน
- ProdigyPlusScheduleFree เป็น Prodigy ที่คำนวณ Learning Rate เองได้อัตโนมัติ ซึ่งต้องการ args เพิ่มเติมต่อไปนี้ weight_decay=0.01 prodigy_steps=470 d_coef=0.05 เน้นไปที่ prodigy_steps เป็นหลักสักประมาณ 25% ของ steps ทั้งหมด
LR Scheduler
เป็นการจัดการว่าเมื่อเทรนนานขึ้นอาจต้องมีการลดลงของ Learning Rate เพื่อให้ model นั้นไปถึงจุดหมายได้ดีขึ้น ในที่นี้จะยกตัวอย่างตัวที่ใช้กันบ่อยๆ
- (แนะนำ) constant — Learning Rate คงที่
- (แนะนำ) cosine — Learning Rate ลดเป็นกราฟ cosine
- inverse_sqrt — Learning Rate ลดตามกราฟตาม inverse sqrt
- linear — ลดเป็นสมการเส้นตรง
- cosine_with_min_lr ตัวนี้เหมือน cosine แต่แทนที่ลด Learning Rate เหลือ 0 ไปเป็นลด Learning Rate ตามที่ต้องการได้ แต่ต้องตั้งค่า min_lr ด้วย
- cosine_with_restarts — ลดตาม cosine แต่ reset ตัวเองกลับไปที่ Learning Rate ที่ตั้งไว้ได้ (เหมาะสำหรับ Lion) ต้องมีการตั้งจำนวน cycles เข้าไปด้วย
- adafactor สำหรับ AdaFactor
- polynomials เป็น scheduler ลดตาม ยกกำลังของ LR Power
สิ่งที่เพิ่มเติมในการทำ Scheduler
- LR Warmup ตัวนี้คือจะค่อยเริ่ม Learning Rate เหลือ 0 ไปยัง ค่าที่ตั้งไว้แล้วค่อยเรียก LR Scheduler เข้ามา ปกติจะตั้งที่ 5%-10% ของ steps ทั้งหมด
คำแนะนำสำหรับการตั้ง LR, Scheduler, Optimizer เบื้องต้น
- ถ้าใช้ AdamW, AdamW8Bit, AdEMAMix, Lion, AdamWScheduleFree กลุ่มนี้ ให้คูณจำนวน batch size เข้าไปยัง learning rate เดิมด้วย เช่น batch size 2 ตั้ง learning rate เป็น
1e-4 * 2 = 2e-4 - ถ้าใช้ constant scheduler ควรตั้ง learning rate ให้น้อยๆ ไว้ก่อน
- ในตระกูล Adam รวมไปถึง AdEMAMix มีค่า betas ที่ช่วยการในมอง dataset ได้เช่น betas=0.9,0.999,0.9999 จะเหมาะกับ dataset ที่เกาะกลุ่มกันเช่น ตัวละคร 1 ชุด, concept ท่าเดียว แต่ถ้าตัด beta2 (betas=0.9,0.99,0.9999) จะดีกับ dataset ที่มีการเหวี่ยงไปมาบ่อยเช่น style, ตัวละครหลายชุด เป็นต้น
สรุปแบบเข้าใจง่ายๆ
- Learning Rate เป็นความเร็วรถสูงสุด
- Optimizer เป็นเทคนิคการขับรถ
- Scheduler เป็นวิธีการขับรถ

Resolution ในการเทรนโดยทั่วไปจะใช้ค่าประมาณนี้ (Max Resoulution)
- 512,512 หรือ 768,768 สำหรับ SD1.5
- 768,768 หรือ 1024,1024 สำหรับ SDXL
- 1024,1024 หรือ 1536,1536 สำหรับ Flux.1
Enable buckets เปิดเสมอ ข้อมูลเพิ่มเติมเกี่ยวกับ Bucket Resolution
Network Rank และ Network Alpha
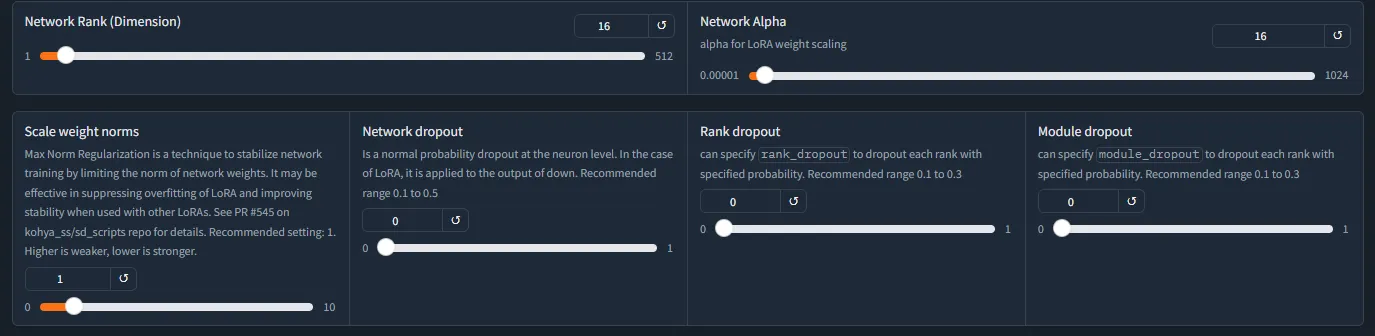
Network Rank
- เป็นการกำหนดขนาดของ LoRA โดยยิ่งใหญ่จำนวน Parameters ที่ใส่เข้าไปได้มากขึ้น ซึ่งยิ่งเยอะยิ่งใหญ่ แต่ทำให้ไฟล์ LoRA ใหญ่ขึ้นด้วย (อาจทำให้คุณภาพดีขึ้นได้ แต่ไม่ใช่เสมอไป)
Network Alpha
- เป็นส่วนที่บอกว่าจะให้ apply weight เข้าไปยัง weight ใหม่แค่ไหน เป็นอัตราส่วน ซึ่งโดยปกติจะใช้กันที่ 50% — 100% ของ Rank
- ตัวละคร network alpha 75%-100%, concept style 50%-100% ได้ หาก LoRA overfitting ลด Alpha ง่ายที่สุด
- ในทางทฤษฏีตั้ง alpha > rank ได้ แต่ไม่แนะนำ
Scale Weight Norm
- เป็นการตัด key ออกไปบางส่วนเมื่อถึงค่า max ที่กำหนดไว้แล้ว ซึ่งการ overfitting จะเห็นได้ง่ายจาก average key norm เริ่มช้าลง หรือ average weight แต่ละ block กลับลดลงเมื่อเทรนนานขึ้น
- ถ้า key scaled พุ่งไปเรื่อยๆ แสดงว่า Learning rate เยอะเกินไปเลยโดนตัดทิ้งรัวๆ (อันนี้นับว่า overfitting เช่นกัน)
- ตั้งประมาณ 1.5–1.7 แล้วให้ average norm อยู่ที่ไม่เกิน 65% ของ scale weight norm
ส่วน Advance — เป็นการปรับรายละเอียดย่อย ซึ่งบางจุดก็ต้องปรับเช่นกัน
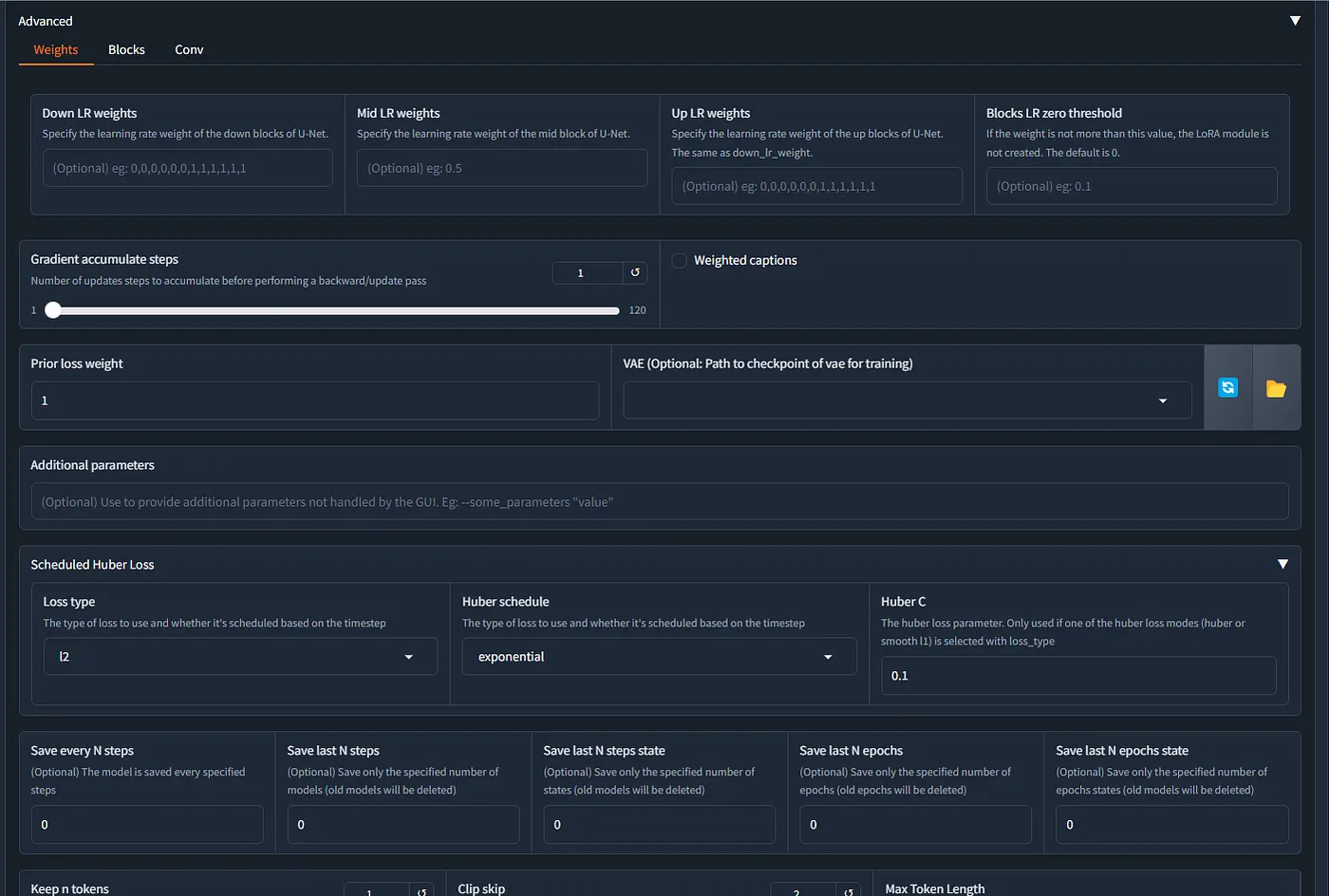
Block Weights
- เราสามารถตั้งให้แต่ละ Block มี อัตราส่วนของ Learning Rate ที่ต่างกันได้ (ต้องดูเรื่องโครงสร้าง unet แต่ละส่วน)
Example (SDXL)
- Down LR weights = 0,0,0,0,0.8,0.8,0,1.1,1.1
- Mid LR weights = 1.1
- Up LR weights = 1.05,1.05,1.05,0.8,0.8,0.8
Additional Parameters
- เป็นการเพิ่ม args ที่ไม่มีใน kohya_ss GUI
Scheduled Huber Loss
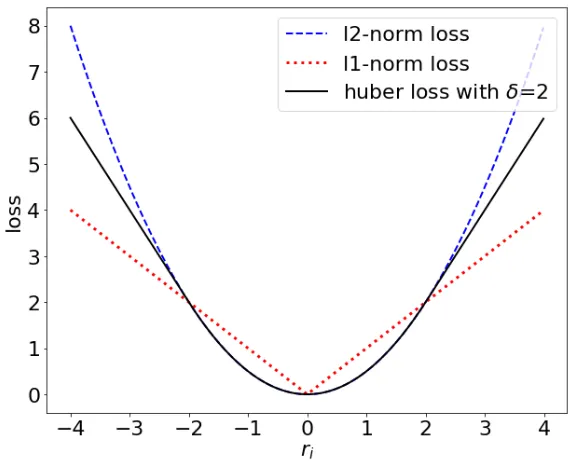
loss เป็นค่าหนึ่งที่เป็นการเปรียบเทียบกับภาพ dataset ซึ่งจะได้ตัวเลขออกมาว่า มันต่างกันเท่าไหร่มันเสียไปเท่าไหร่ ซึ่งค่านี้เอาไปใช้ในการคำนวณ gradient ได้ โดยแบ่งออกเป็นดังนี้
- l1 กราฟ absolute เส้นตรง
- (แนะนำ) l2 parabola
- huber เป็นการสลับ l2 กับ l1 โดยผ่าน huber scheduler และ huber c ช่วยสู้กับ dataset ที่โดดไปโดดมาได้ แนะนำตั้ง SNR และ 0.85 ตามลำดับ
Keep n tokens และ Max Token Lengths
- Max token ให้เลือกเยอะที่สุด (แนะนำ) 225
- Keep n tokens = 1 อันนี้มีผลเฉพาะ tag based caption โดยแบ่งด้วย comma 1 หมายถึง 1 tag โดยเพิ่มได้เรื่อยๆ
Advance Parameters อื่นๆ
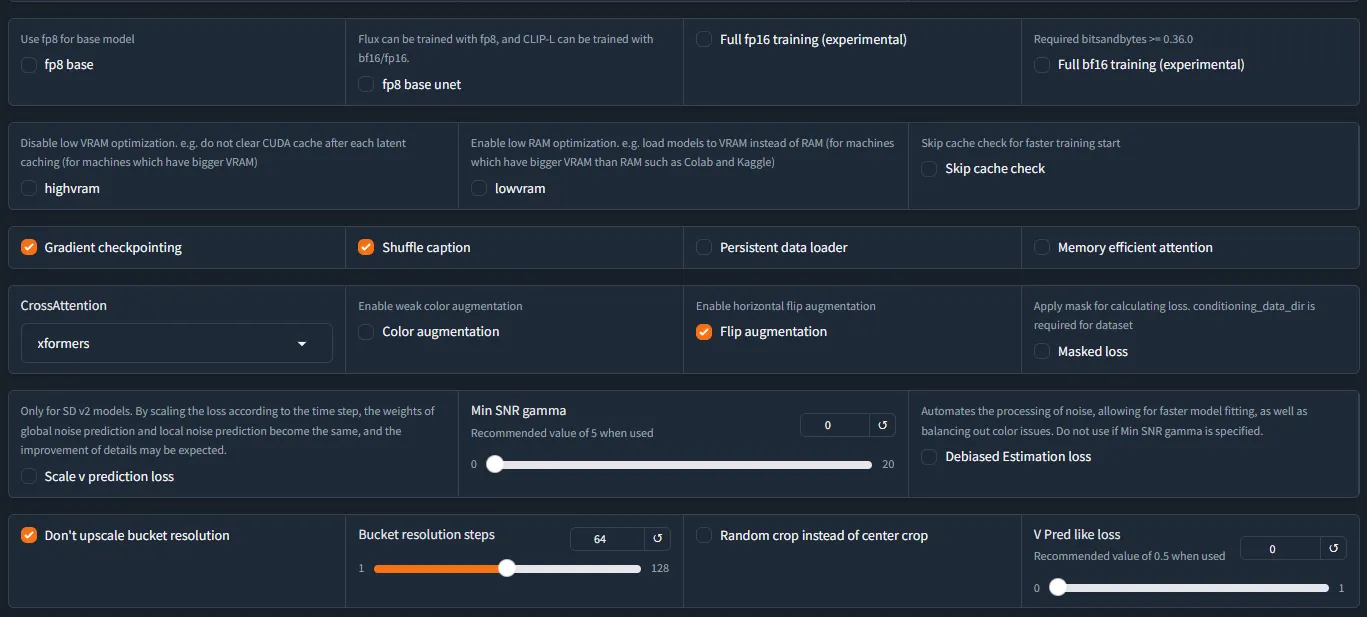
- (แนะนำ) Gradient checkpointing ติ๊กเพื่อลด VRAM
- Shuffle caption ใช้กับ tag based caption ใช้ร่วมกับ keep n tokens
- (แนะนำ) Full bf16 training (experimental) ติ๊กหมดยกเว้นกลุ่ม ScheuduleFree
- fp8 base อันนี้ใช้กับการเทรนบน vram 8 GB ได้แต่รายละเอียดหายไปเยอะ
- fp8 base unet (ถ้าใช้ Flux.1 Dev fp8)
- Color Augmentation เป็นการแปลงสีนิดๆ หน่อยๆ ใน dataset
- Flip Augmentation เป็นการ flip ภาพแบบ horizontal ใน dataset
(Optional) Noise Offset
(แนะนำ และเป็นค่าเริ่มต้น) Original

- แบบสุ่มมั่วๆ ไป
Multires เป็นการทำให้การสุ่มของ noise มีเป็น pattern มากขึ้นโดยมีการปรับ 2 ค่าคือ Multires noise iterations กับ Multires noise discount อาจช่วยในการทำ style หรือ หน้าคนได้ ใน dataset ที่จำกัด


- Multires noise iterations เป็นการเพิ่มขนาดของ noise ให้ใหญ่ขึ้นยิ่งมากทำให้ภาพเน้นการโฟกัสไปที่ภาพรวมมากขึ้น
- Multires noise discount คือเป็นการที่ปรับระดับการเพิ่ม noise เข้าไปยิ่งน้อยยิ่งเก่งรายละเอียดเล็กๆ
Dropout caption every n epochs
- เป็นการตัด caption เมื่อ epoch เพิ่มขึ้น เพื่อให้ภาพเรียนรู้สิ่งนั้นโดยไม่มี caption ซึ่งอาจช่วยในการเข้าใจภาพโดยไม่ต้องอธิบายได้ดีขึ้น (เหมาะกับ style) ใช้ร่วมกับ Rate of caption dropout
(Optional) Logging
- ปกติเราจะใช้ tensorboard ในการเก็บข้อมูลเช่น ประวัติของ learning rate ค่า loss เฉลี่ย เป็นต้น เพื่อเช็คการทำงานของการเทรนว่าทำงานถูกต้องหรือไม่
(Optional) Save Training State

- ใช้ในกรณีที่เราเหมือนสามารถหยุดเวลาแล้วเก็บสถานะไว้ได้ และเอากลับมาเทรนต่อจาก steps เดิมได้เลยหากไฟดับ หรือ เกิดปัญหาที่ทำให้โปรแกรม crash
- ตัวนี้สามารถเปลี่ยน parameters ได้บางส่วน
(Optional) Samples
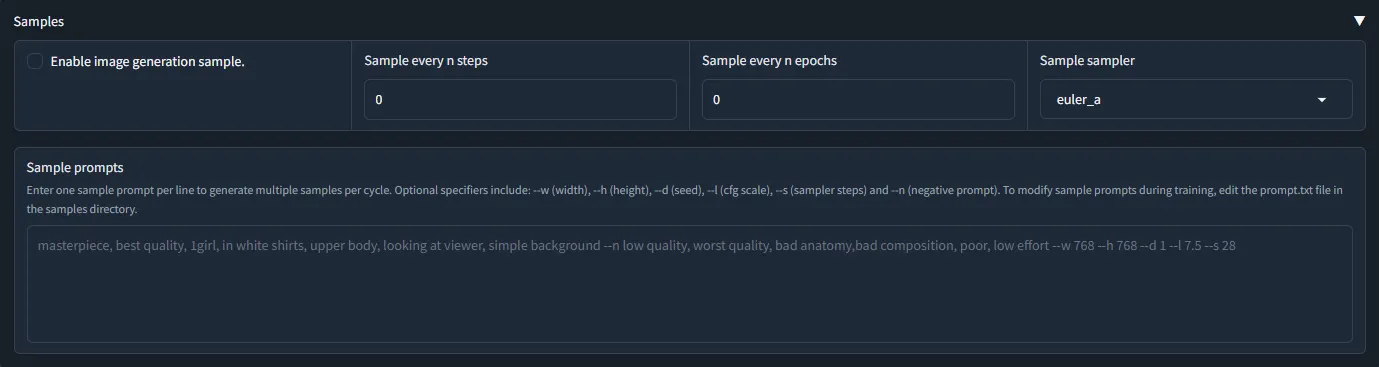
- ใช้ในการเจนภาพเมื่อถึง epoch ที่กำหนดผ่าน prompt ที่ได้ตั้งไว้
Parameters เฉพาะใน SDXL

- (optional) Cache Text Encoder Output ประหยัด VRAM แต่ไม่สามารถ shuffle caption ได้
- (optional) No Half VAE
Parameters เฉพาะใน Flux.1 (เฉพาะพื้นฐานที่ปรับกัน)
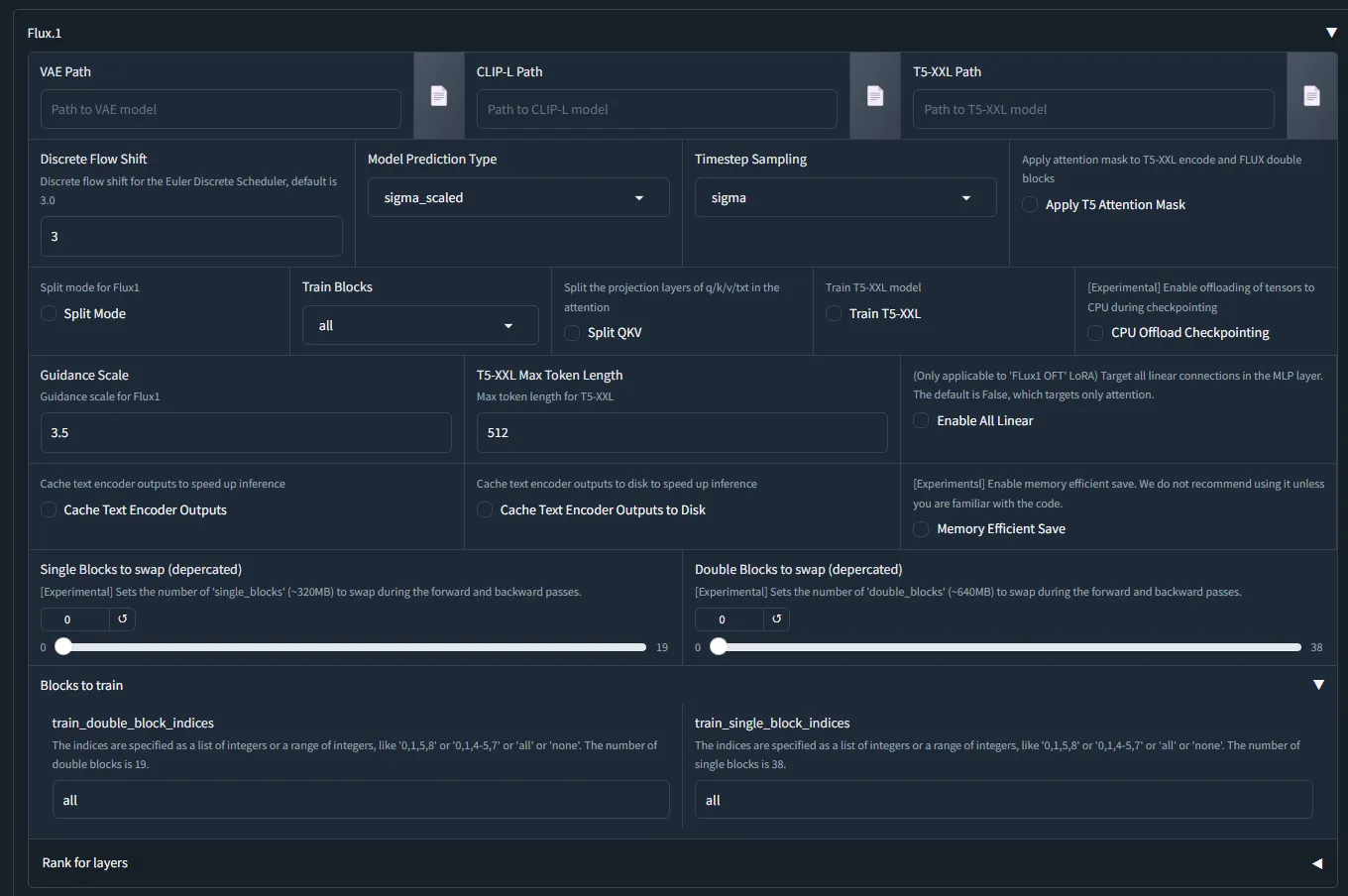

Parameters ที่ต้องตั้งสำหรับ Flux (จากตัวอย่างที่ kohya-ss ให้มา)
- Model Prediction Type = raw
- Timestep Sampling = sigmoid
- Guideance Scale = 1
อื่นๆ
- ต้องมีการตั้ง Path ของ VAE, CLIP-L และ T5XXL
- Blocks to swap อันนี้ใช้เพื่อสลับ unet block เข้าออก RAM -> VRAM ซึ่งต้องมี RAM เผื่อไว้ด้วย โดยมากสุด 36 blocks to swap ยิ่งเยอะยิ่งช้าในการเทรนแต่ละ step
- VRAM 16 GB อาจไม่ต้องใช้ แต่ต้องเลือก batch_size = 1
- VRAM 12 GB ใช้ 16 blocks to swap
- VRAM 10 GB ใช้ t5XXL fp8 และ 22 blocks to swap
- VRAM 8 GB t5XXL fp8 และ 28 blocks to swap
รูปแบบการ Train Flux.1 LoRA
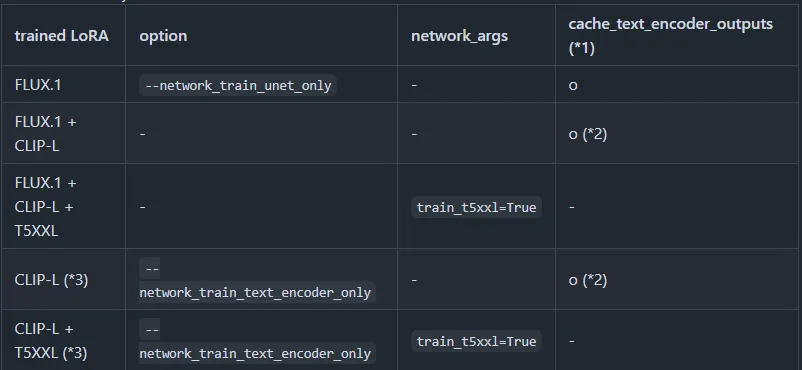
- ถ้าเทรน T5XXL ด้วย ต้องเผื่อ VRAM (RAM) ไว้อีก 6GB
หากตั้งค่าครบถ้วนแล้วสามารถกด Start Training ได้เลย

4. การตรวจสอบ LoRA ผ่านเครื่องมือ inspector ต่างๆ
เมื่อทำการ Train LoRA สำเร็จการที่นำ Model LoRA มาตรวจสอบสามารถได้ด้วยวิธีการต่างๆ ดังนี้
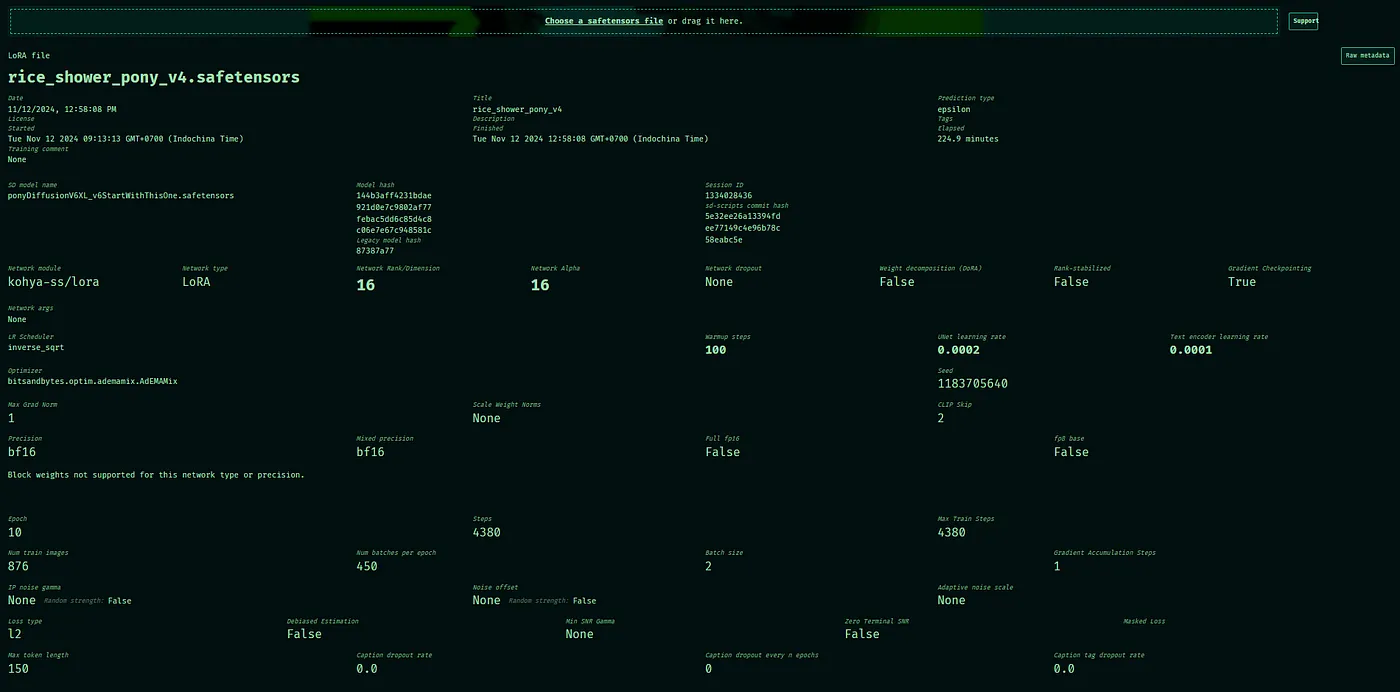
- ใช้ https://lora-inspector.rocker.boo/ เว็บนี้รองรับ LoRA fp16 เท่านั้นสำหรับการดู weight แต่ละ block และ สามารถดูข้อมูลพื้นฐานได้
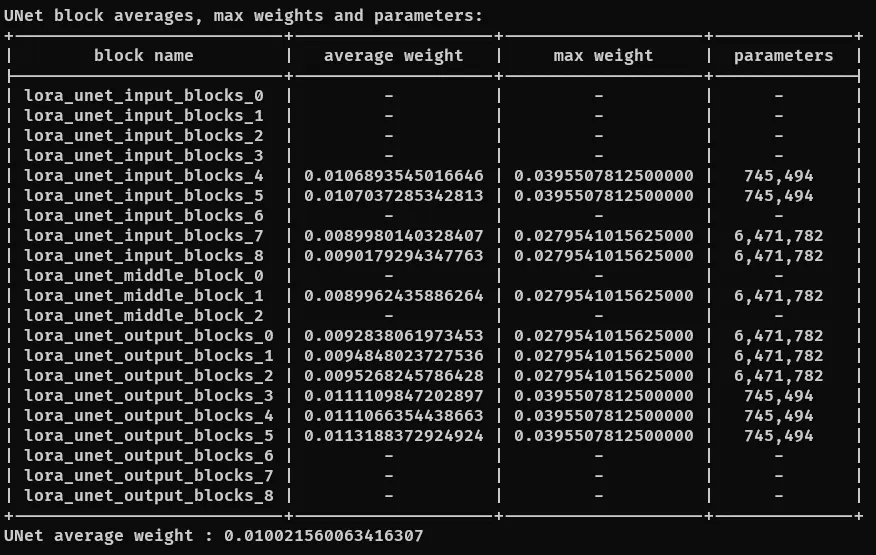
- LoRA Parameters (พัฒนาโดย vjumpkung + Gtonero) เป็นโปรแกรมที่ตรวจสอบ weight แต่ละ block ได้อย่างละเอียด (มีการปัดจุดทศนิยมเพื่อให้อ่านง่ายขึ้น) ช่วยในการตรวจสอบ overfitting ได้ง่ายขึ้น รองรับ ทั้ง bf16 และ fp16 LoRA

- วิธีสุดท้ายคือนำเอา LoRA มา XY Plot เพื่อดูแต่ละ epoch แล้วเลือก epoch ที่พอใจที่สุด ซึ่งวิธีนี้อาจต้องใช้หลายๆ prompt เพื่อเช็คอาการ overfitting ก่อน
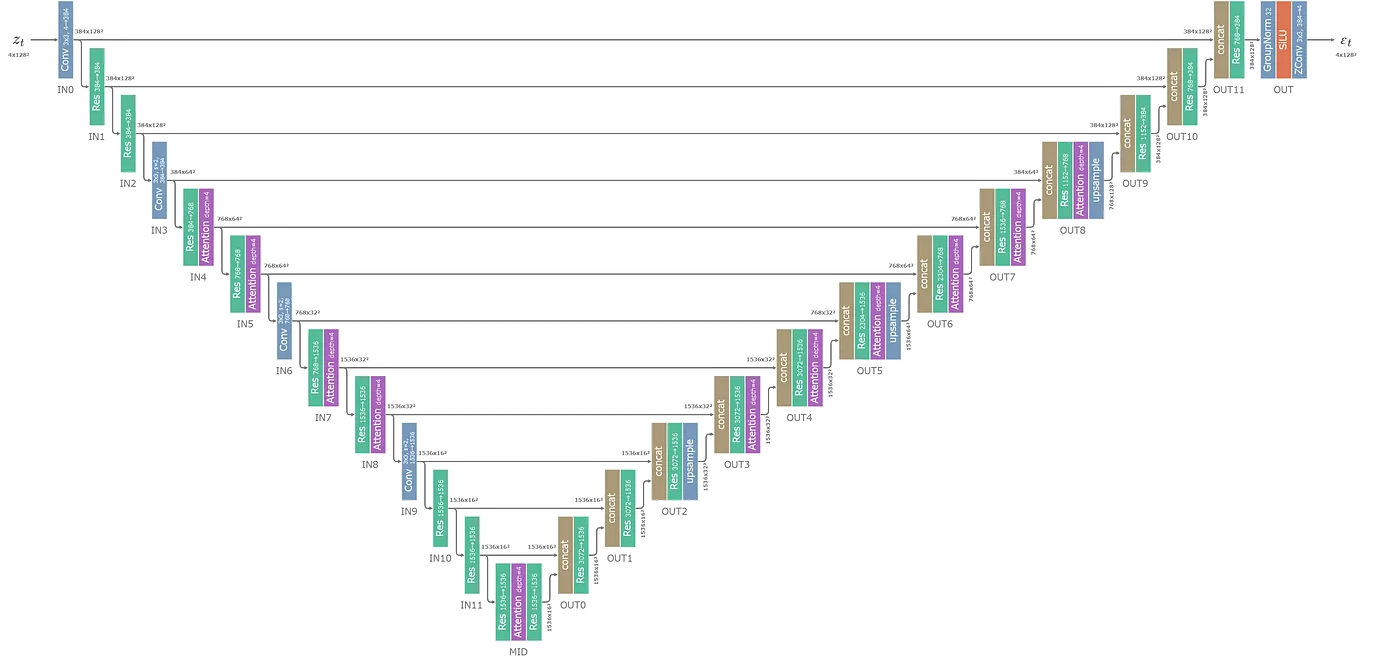
- UNet แต่ละ block จะมีผลต่อ LoRA ที่แตกต่างกัน โดย SDXL, Pony มีผลที่ OUT0, OUT1, OUT2
5. (แถม) การบีบอัด LoRA เพื่อลดขนาดไฟล์
- การบีบอัด LoRA มีข้อดีคือทำให้ไฟล์มีขนาดเล็กลงและ โหลดเร็วขึ้น
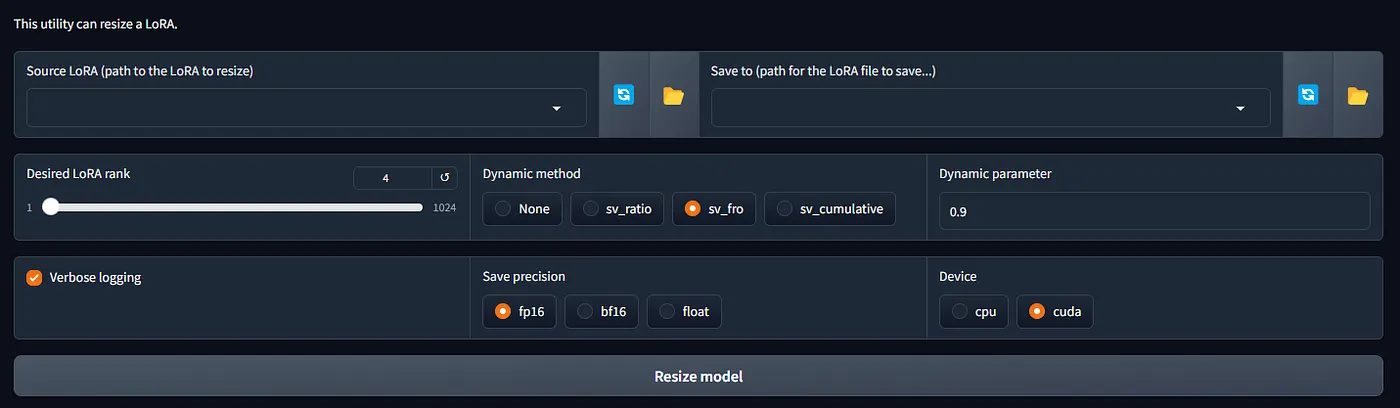
การตั้งค่ามีการปรับต่อไปนี้
- Desired LoRA Rank คือ Network Rank สูงสุด
- Dynamic Method อันนี้คือเป็นการคำนวณว่าให้แต่ละ block มี rank เท่าใด โดยมีวิธีทั้งหมด 3 วิธีคือ sv_ratio, sv_fro, sv_cumulative และ dynamic parameters อ่านเพิ่มเติมได้ที่ civitai ปกติจะใช้ sv_fro ส่วน None หมายถึงทุก rank เท่ากันหมด
- sv_fro กับ sv_cumulative เป็นการบอกว่าจะให้ LoRA จดจำจาก rank เดิมกี่ %
Dynamic parameter
- เป็นตัวเลขของแต่ละ sv ที่ต้องการจะไม่เหมือนกัน
- sv_ratio ต้องการ Dynamic parameter ≥ 2
- sv_fro และ sv_cumulative ต้องการ 0 < Dynamic parameter < 1
สิ่งที่อยากฝากคนที่อยาก Train LoRA
- สูตรสำเร็จ ไม่มีเสมอ เพราะว่า dataset กับ total steps ที่ต่างกัน และค่า loss ที่โมเดลคำนวณได้ที่ต่างกันเสมอ
- บทความนี้บางส่วนมาจากประสบการณ์อยู่บ้าง หากมีประสบการณ์มากพอจะมีการอัพเดทเรื่อยๆ
- อนาคตอาจมีการทำ video สอนตั้งแต่ติดตั้งโปรแกรม และการ Train LoRA
Fun Fact
- kohya_ss คือผู้สร้าง script ในการเทรน LoRA เรียกว่า sd-scripts เป็น python file และ bmaltais นำ sd-scripts มาสร้างเป็น GUI ใช้งานผ่านบนเว็บเรียกว่า kohya_ss
- การเลือกการ์ดจอให้ดูที่ FP32 Theoretical Performance หน่วย TFLOPS
- การทำ mixed precison คือ การเทรนโมเดลด้วย FP ที่แตกต่างกันทำให้เราสามารถเร่งความเร็วในการเทรนได้
Reference
